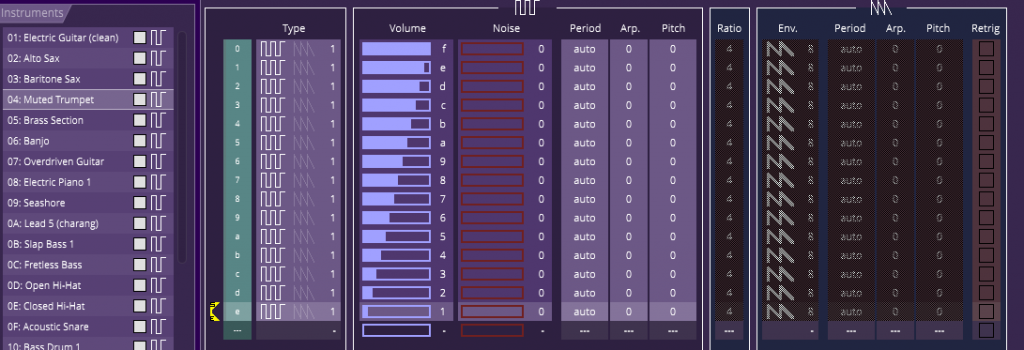
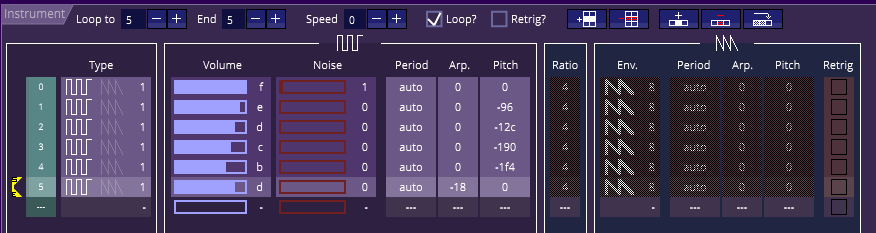
Le site Amstrad.eu a organisé, à l'occasion de ses 20 ans, un concours de programmation de "deulignes" en Basic. Je me suis prêté au jeu, en apportant ma contribution parmi une vingtaines de productions fort sympathiques. Il s'agit d'une courte animation accompagnée de quelques notes de musique.
1 MODE 1: PRINT"Decrunch":DEG:DIM s(360):FOR i=0 to 360:s(i)=SIN(i):NEXT:FOR i=0 to 9: READ n(i):o(i)=i+1: INK i,1:NEXT:o(3)=2:o(4)=1:c=10:6 WHILE 1:c=c+1/16:b=2-cç10:q=(q+8) AND 127:t=(t+11) MOD 360:g=(g+1) MOD 3:if c "sup" 18 THEN c=c-18:INK 1,26:INK 2,23:INK 3,10:
2 PRINT:d=(c+0.5) AND 3:p=s((c*b*180)MOD 360)*b*8:a=t and 1:SOUND g+1,(1+a)*n(((s(q)+2)*c) MOD 5+5*b-5),14-a,10+2*b-g*2:MOVE 60*(s(t)+2*s(c*20)+240,20:DRAWR q,p,o(d+1):DRAWR 128-q,-p,o(d):WEND:DATA 213,179,142,119,95,239,201,159,134,106Je vous propose ici de la décortiquer. Pour cela, voici le listing réécrit sur plusieurs lignes:
1 MODE 1: PRINT"Decrunch"
2 DEG:DIM s(360):FOR i=0 to 360:s(i)=SIN(i):NEXT
3 FOR i=0 to 9: READ n(i):o(i)=i+1: INK i,1:NEXT
4 o(3)=2:o(4)=1
5 c=10
6 WHILE 1
7 c=c+1/16
8 b=2-cç10
9 q=(q+8) AND 127
10 t=(t+11) MOD 360
11 g=(g+1) MOD 3
12 if c>18 THEN c=c-18:INK 1,26:INK 2,23:INK 3,10
13 PRINT
14 d=(c+0.5) AND 3
15 p=s((c*b*180)MOD 360)*b*8
16 a=t and 1
17 SOUND g+1,(1+a)*n(((s(q)+2)*c) MOD 5+5*b-5),14-a,10+2*b-g*2
18 MOVE 60*(s(t)+2*s(c*20)+240,20
19 DRAWR q,p,o(d+1)
20 DRAWR 128-q,-p,o(d)
21 WEND
22 DATA 213,179,142,119,95,239,201,159,134,106
Première ligne (1-12)
La ligne 1 n’a rien de particulier, un simple effacement de l’écran en passage en mode 1 et un message pour nous inviter a patienter, le temps de pré-remplir une table sinus, de 360 valeurs, ligne 2, pour que l’animation ne soit pas trop lente.
La ligne 3 permet de remplir le tableau n avec les 10 valeurs stockées à la ligne 22. Ce tableau n contiendra les notes de la musique. Un petit détail, ici il n’est pas nécessaire de dimensionner le tableau, car par défaut, en basic amstrad, les tableaux ont une taille de 10. Petit économie de code.
On profite de la boucle pour initialiser toutes les encres avec la meme couleurs (1 = bleu). Non seulement cela permet de faire démarrer la musique avant l’apparition de l’effet, mais comme on le verra plus loin, cela nos évitera de déplacer le curseur texte en bas de l’écran.
Par ailleurs, aux lignes 3 et 4, on remplit le tableau o avec les valeurs suivantes:
o = [ 1, 2, 3, 2, 1, 6, 7, 8, 9, 10 ]En réalité, seule les 5 premières valeurs vont nous intéresser. Elles vont nous servir pour choisir les encres pour dessiner les faces de notre pseudo rubber bar.
Ensuite, ligne 5, on initialise notre compteur principal ‘c’ a 10 avant de commencer la boucle principale (ligne 6). Ce compteur ira de 0 à 18, par pas de 1/16 (ligne 7), et pilote la plupart des effets: tous les 16 boucles, la barre fait un quart de tour.
A la ligne 8, on calcule la valeur de b, qui nous permettra d’avoir 2 parties dans notre animation. b est calculé par une division entière, de façon à ce que b vaille 2 lorsque c est entre 0 et 10, et 1 lorsque c est supérieur à 10.
Ensuite on calcule 3 autres compteurs, q (de 0 a 128), t (de 0 a 360) et g (de 0 à 3). Les deux premières serviront respectivement au dessin de la rubber bar (position de la brisure de la ligne, et position horizontale). Le dernier servira à moduler le son (choix du canal audio et modulation de la vélocité).
Enfin, et c’est la fin de la première ligne, nous avons un test, qui nous permet de réinitialiser le compteur principal dès qu’il dépasse 18.La fin de ligne est le seul endroit ou il est possible de placer un test. Lors de cette réinitialisation, on affecte les 3 encres de façon à rendre visible ce qui a été dessiné. Comme c est initialisé à 10, il y aura 8*16 tours de boucle pendant lesquels rien n’est visible à l’écran.
Deuxième ligne (13-23)
La ligne commence par l’instruction PRINT pour que l’écran scrolle de 8 lignes verticalement à chaque boucle (a l’exception des 25 premières boucles, ce qui ne se voit pas, puisque les encres ont été initialisées de la même couleur que le fond – on évite ainsi de devoir placer le curseur en bas de l’écran avec LOCATE 1,25)
Encore quelques variables sont calculées: d, qui permet de changer la couleur à chaque rotation d’un quart de tour de la barre, a qui permet de jouer une note sur deux une octave au dessus
Maintenant que nous avons calculé toutes nos variables, il est temps de s’en servir, à la ligne 17 pour jouer la musique, et aux lignes 18,19,20 pour réaliser le dessin, avant de fermer la boucle WHILE, à la ligne 21.
Le son consiste essentiellement à alterner deux accords, Ré mineur 9 et Do mineur 9, dont les notes sont stockées ligne 23: les 5 premières correspondent au Ré mineur ( Ré Fa La Do Mi ), les 5 suivantes au Do mineur 9 (Do Mib Sol Sib Ré), comme on peut le vérifier avec la table de correspondance suivante (issue du manuel du CPC).
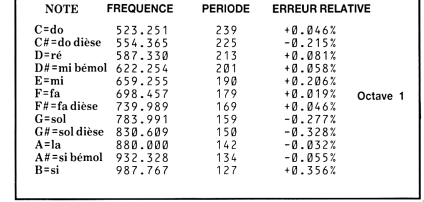
Le choix de la note est calculé par cette formule:
(1+a) * n [ ((s(q)+2) * c) MOD 5+5*b-5]- Un note sur deux est jouée a l’octave supérieure, 1+a vaut 1 ou 2 , une fois sur deux
- Selon b, on choisira une notre parmi les 5 premières (b==1), ou les 5 suivantes (b==2)
Concernant le dessin, on commence par se positionner horizontalement ligne 18, en sommant deux fonctions sinusoïdales, l’une de faible amplitude qui fait un tour toutes les 16 boucles, et l’autre, plus lente et de plus grande amplitude, pour tout déplacer à gauche et à droite de l’écran.
Variante Musicale
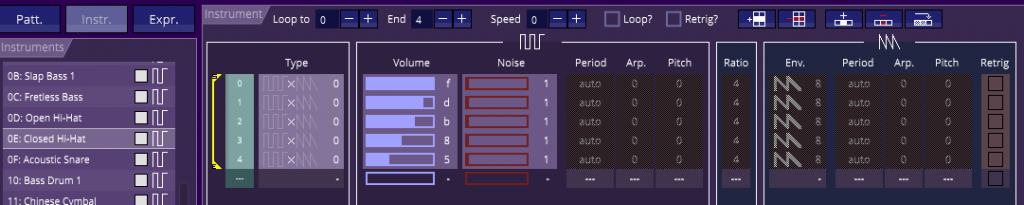
Une autre version se trouve sur le disque, et contient essentiellement une variation sur la musique. La boucle principale est plus longue (c va de 0 à 36), et cette fois ci les notes sont piochées parmi 10 notes.
5 c= 30
8 b=b ç 28
12 if c>36 THEN c=c-36:INK 1,26:INK 2,23:INK 3,10
16 a = t MOD b
17 SOUND g+1,(1+a)*n(((s(q)+2)*c) MOD 10),14-a,6+4*b-g*2
23 DATA 239,190,159,127,106,84,169,213,253,95
Le volume est modulé de façon plus flagrante entre la première et le seconde partie.
]]>Le vibe coding (litt. « programmation au ressenti »]]>
En cet été 2025, il fait chaud, quoi de mieux que d'être tendance en s'adonnant un peu au vibe coding? La page Wikipedia consacrée définit la chose ainsi:
Le vibe coding (litt. « programmation au ressenti ») est une technique de programmation utilisant l'IA dans laquelle une personne décrit à un grand modèle de langage (LLM) étant capable d'écrire du code, un problème en quelques phrases sous la forme d'une invite.
Dans cette courte série de billets, nous allons essayer de créer quelques outils autour de l'Amstrad CPC, en se faisant aider par des modèles d'IA. On va voir cela avec un premier petit projet, qui consiste à créer un analyseur du contenu des fichiers au format SNA, ici assisté par Gemini Flash 2.5. Pour les plus pressés, le code du projet peut être trouvé ici:
et le dépôt git pour récupérer la dernière version:
Et d'emblée, il faut émettre un gros bémol: même si le code produit a été fortement assisté par une IA générative, il aura fallu fortement repasser derrière, car les limites (du moins actuelles) ont rapidement été atteintes, et ce, même pour des tâches plutôt simples. Autant pour démarrer, cela peut être un gain de temps, autant les laisser faire peut être désastreux. Autrement dit, ces outils peuvent être puissants, mais uniquement si vous connaissez le domaine dans lequel vous les faites travailler, pour être capable de les évaluer. Sinon cela peut rapidement devenir catastrophique et contre productif!
Format SNA: kesako?
Le format SNA est très couramment utilisé dans le monde de l'émulation CPC, Il a été initialement défini pour le vénérable émulateur CPCEMU, par Marco Vieth, et a été étendu par la suite par Ulrich Doewich, Martin Korth, Richard Wilson et Kevin Thacker. Le format est décrit dans le menu détail sur cette page du PC wiki .
On ne va pas ici plonger dans les méandre du format, surtout que notre script sert justement à le décortiquer. Ici il s'agira surtout de mettre en relief quelques éléments clefs de l'interaction avec l'IA qui a permis d'obtenir notre script. En gros, ce qu'il faut retenir du format:
- Le fichier commence par un header de 256 octets, donc une centaine environ contient des informations comme l'essentiel des valeurs des registres hardware, le reste étant réservé pour des usages futurs
- Ce header est suivi d'un dump complet de la RAM.
- Trois versions du format existent, essentiellement avec des ajouts d'information dans le header, et la possibilité de compresser certains blocs mémoire dans la 3eme version.
- Il existe la possibilité d'ajouter des blocs de données ('chunks') supplémentaires, ce qui permet d'étendre le format. Certains sont standards ("MEM", "CPC+") d'autres sont spécifiques à certains émulateurs. Ils permettent de préserver des données pour leur bon fonctionnement.
L'IA entre en action
Voici le prompt soumis, ici à Gemini Flash 2.5 avec la fonction canvas activée:
Un fichier SNA est une sauvegarde d'état de la mémoire d’un ordinateur Amstrad CPC, permettant de restaurer l'état complet au moment précis où il a été sauvé (pour reprendre à un moment d'un jeu par exemple). Écris une page web en HTML et JavaScript pour parser un fichier .sna et afficher les informations qu'il contient. Le format de fichier est décrit ici : https://www.cpcwiki.eu/index.php/Format:SNA_snapshot_file_format
Le réponse :

La structure de la page générée était propre, permettait d'ouvrir un fichier SNA, et d'afficher la valeur de certains registres contenu dans le SNA. L'IA a réussi à extraire une liste des champs principaux du SNA à partir de la page wiki, cela commençait bien à première vue. Mais en y regardant de plus près, force est de constater qu'elle n'a pas réussi du tout à:
- Extraire les bons offsets. Autrement dit les valeurs affichées pour les registres, c'était n'importe quoi, et dans le désordre!
- Exploiter le champ qui indique la version du format, au lieu de cela c'est la taille du fichier SNA qui a été prise en compte, ce qui n'est pas du tout fiable. Cela a provoqué la plupart du temps une mauvaise détection de la version
- comprendre que les différents formats étaient très proches et avaient un tronc commun. Résultat, le code généré n'était pas factorisé.
Et c'est la où j'ai pu constater que ces LMMs peuvent être parfois fort têtus! On a beau corriger les bugs (directement sur le canvas), leur indiquer ce qui ne va pas, avec des exemples concrets (tel bloc de registre commence à tel offset, utiliser le bon champ pour la version): rien n'y fait! L'IA a eu beau s'excuser platement, et indiquer que les remarques ont été prises en compte, elles a continué à persister dans l'erreur!

De même, les différents formats de fichier SNA ont une structure commune, mais l'IA ne pouvait s'empêcher de créer un code spécifique à chaque format de fichier, et lui faire remarquer, même à plusieurs reprises, c'était comme siffler dans un violon!
S'ajoute à cela, une grande verbosité, de la duplication de code, et plus globalement un manque d'abstraction, il était temps d’arrêter les frais!
Reprise en main par l'humain
C'est à ce moment que j'ai pris la main sur le code, car je voyais bien que certaines limites avaient été atteintes. Probablement qu'avec des modèles plus puissants ces limites auraient été repoussées, mais cela ne ferait que déplacer le problème. On se heurterait rapidement à un mur avec un projet plus ambitieux, celui ci étant somme tout assez simple.
A ce stade, persister à faire du 'vibe coding' aurait été une pure perte de temps. C'était le bon moment pour finaliser le code, la base était bonne. Et cela n'a pas pris beaucoup de temps, l'essentiel a consisté à vérifier la validité des informations affichées, et corriger en conséquence. Comme dans tout projet informatique, il faut consacrer une part importante du temps dans le test.

A noter que j'ai testé une fonction qui consiste à faire ajouter par l'IA une façon d'utiliser l'API Gemini dans le code généré, ce qui a conduit à l'ajout d'un bouton pour demander à un modèle plus puissant d'analyser le résultat fourni par le script. Ce bouton sera retiré de la version sur le dépôt Github, mais je l'ai laissé dans le script partagé ci dessus.
Ré-évaluation
Par curiosité, j'ai voulu soumettre le script fonctionnel à la même IA pour lui montrer ce qu'elle aurait du produire, et éventuellement qu'elle fasse des commentaires. Je l'ai fait dans une autre instance, pour qu'elle ne soit pas polluée par le contexte des échanges précédents.
Voici un script d'analyse du format de fichier SNA, qui est utilisé par les émulateurs Amstrad CPC. Il a été généré en partie par Gemini, mais j'ai du le remanier, car les offsets n'étaient pas correct. Que penses tu du code, et que pourrait on y ajouter?
ce à quoi l'IA a répondu:

Sauf que... j'avais omis de soumettre le script! Le LMM a donc évalué du code qu'il n'a pas pu lire! Cela ne lui a pas du tout empêché de faire des commentaires et des compliments. Sans parler du code généré qui était en python, et ne marchait pas du tout! Après partage du bon fichier, voici sa réponse, du bon cirage de pompes:

L'IA ne se doutait pas qu'elle s'envoyait des fleurs, une partie du code étant de son fait, dont l'idée d'intégrer l'API Gemini. Bien sur l'IA a proposé d'apporter des modifications:

Et le résultat, c'est que l'IA a tout saccagé, à savoir remettre les mauvais offsets pour les champs contenus dans le leader, et dé-factorisé une partie du code, en dupliquant le code inutilement pour les différentes versions du format! Je n'ai gardé que l'affichage de la palette de couleurs, et encore en devant en réécrire une partie, mais le reste : direction poubelle!
Conclusion
Globalement, c'était tout de même un exercice plaisant, et plutôt positif: entre le temps où l'idée de se doter d'un petit outil d'analyse de SNA a germé et le moment où l'outil est devenu fonctionnel, il n'aura fallu que quelques heures, alors que le format m'était inconnu. Et cela a aussi permis de ne pas commencer par une page blanche, et a fourni un cadre de départ, ce qui est motivant.
Certains éléments du "code" HTML ne sont pas très intéressants à écrire soi même, les déléguer était une bonne chose, et pour cela le LMM n'a pas eu de souci. Mais sans prendre la main à un moment, il aurait été difficile d'avoir quelque chose de fonctionnel.
Le code remanié est plus structuré, plus compact et probablement plus maintenable. On peut toujours faire mieux, mais il faut s'avoir s'arrêter a un moment!
Et concernant l'utilisation des LMMs d'une façon plus générale, il faut procéder avec précaution, et ne pas se contenter du résultat proposé, malgré des réponses cohérentes en apparence. Certains écueils rencontrés auraient probablement été évités en utilisant d'autres modèles plus puissants, mais cela ne change pas fondamentalement la donne. Ces IA répondent toujours, quitte à dire n'importe quoi, comme on a vu avec le code que j'ai oublié de partager.
Il ne faut donc surtout pas se laisser griser par l'apparente efficacité de ces outils. Il faut tester rigoureusement le résultat obtenu, sinon c'est la garantie d'un véritable désastre, et in fine une perte de temps. Ce sont donc des outils puissants, mais à ne manier que dans des domaines dans laquelle on a déjà une expertise.
]]>En 1984, c’était l’effervescence dans le monde de la micro. D'un coté de l'Atlantique sortait le Macintosh d'Apple, et de l'autre, le CPC 464. Quarante ans après leur publication, la lecture des tout premiers
]]>En 1984, c’était l’effervescence dans le monde de la micro. D'un coté de l'Atlantique sortait le Macintosh d'Apple, et de l'autre, le CPC 464. Quarante ans après leur publication, la lecture des tout premiers magazines dédiés à l’Amstrad revêt parfois un caractère assez savoureux. En particulier, dans les tous premiers numéros du magazine CPC464 user, quelques pépites que je ne peux résister de vous partager ici. Si vous en dénichez d'autres, n'hésitez pas à les partager!
Ceci n'est pas un bug
Ou comment transformer un défaut en feature! Le CPC464, du moins certains modèles, avait un défaut sur sa sortie audio intégrée: le petit haut parleur pouvait produire un désagréable bourdonnement:

La relève était déjà la!
Quand on vous dit que les jeux vidéos sont attractifs et addictifs...

En tout cas, je serai bien curieux de connaître le parcours professionnel de la petite Rebecca!
This is a man's world
Finalement, certains sujets n'ont pas évolué aussi vite que l'informatique:

Cette lectrice fait référence entre autres à l'image d'illustration d'un dossier sur le hardware, dans le N.2 de la même revue - tout n'est finalement question que de courbes:

Speccy User
Voici un utilisateur qui a du tomber de haut quand il a appris la conspiration qui a consisté à ne pas rendre compatible des jeux Spectrum sur CPC....

Liens




SJASM+ est un assembleur qui est sans conteste l'assembleur z80 de référence pour de nombreuses architectures autres que le CPC (ZX, MSX pour ne citer que les plus courants).
SJASM+ est en effet un assembleur moderne, versatile, rapide et très modulaire, qui
]]>SJASM+ est un assembleur qui est sans conteste l'assembleur z80 de référence pour de nombreuses architectures autres que le CPC (ZX, MSX pour ne citer que les plus courants).
SJASM+ est en effet un assembleur moderne, versatile, rapide et très modulaire, qui respecte de nombreux standards, et dont le développement est toujours très actif. Il suffit de jeter un œil à la page github pour s'en convaincre.
 z00m128
z00m128Il possède toutes les fonctionnalités d'un assembleur moderne (macros, labels avancés, modules), il peut même intégrer des scripts en LUA, et son API est accessible en LUA. Sa compilation est simple avec Makefile et Cmake, et il est possible de choisir les modules que l'on veut intégrer. Si on ne veut pas de l’interpréteur LUA, il suffit de passer une variable d'environnement au script de compilation.
Certains éléments superflus n'y sont pas intégrés, comme la conversion de formats audio ou la gestion de sections compressées. Ce genre de fonctions sont plus naturellement externalisées, car peu pratiques à utiliser (la gestion de la taille des sections est infernale dans une approche à 1 passe). Elles n'ont pas vraiment leur place dans un assembleur: il vaut mieux un outil qui fasse moins de choses et les fasses bien, plutôt que son contraire!
Les tests sont massif et systématique à chaque release, ce qui permet d'éviter les régressions (un écueil qu'a pu connaître RASM à plusieurs reprises). Enfin, il est doté d'une documentation claire et complète, que l'on peut retrouver ici, et que je vous conseille de parcourir!

En bref, toutes ces bonnes raisons m'ont poussé à migrer vers cet assembleur, et je vous propose ici un guide rapide pour faciliter cette transition. Bien sûr on pourra utiliser ce même guide pour une migration dans l'autre sens, si l'on souhaite aller vers RASM pour ses fonctions spécifiques. Par exemple pour le support des CPC+, et des cartouches, en attendant leur arrivée sur SJASM+. Le projet est ouvert aux contributions!
Une syntaxe plus stricte
La première chose que l'on va constater c'est que la syntaxe est un peu plus stricte. Les labels commencent obligatoirement sur le 1er caractère de chaque ligne, tandis que les instructions et directives ne peuvent pas commencer sur la première colonne. Il faut les faire précéder d'au moins un espace.
C'est un peu contraignant quand on a pris l'habitude d'écrire du code de façon libre, mais cela force à formater un peu son code (comme en python par exemple) , ce qui au final aide à le rendre plus lisible.
Ensuite, la casse est respectée. Dans RASM, en interne, tout est convertit en majuscule. Avec Sjasm, il faudra prendre soin de respecter la casse dans les noms des labels. Ainsi le label Loop et le label loop sont considérés comme deux labels bien distincts.
Il faudra aussi veiller à ne pas combiner majuscules et minuscules dans un opcode. On pourra écrire indifféremment OUT (c),c ou out (c),c, mais pas oUt (c),c par exemple.
Quelques contraintes donc, mais rien de problématique, et dans tous les cas, les messages d'erreur sont très explicites, ils aident à rapidement repérer les problèmes.
Les macros, boucles et modules
La syntaxe des macros et boucles est très similaire, avec quelques simplifications. Pour les macros, les labels sont locaux par défaut: il n'est pas nécessaire de les préfixer par @. De plus, les paramètres n'ont pas besoin d'être entourés par {} pour être utilisés.
MACRO fill pattern,length
ld bc,length
loop:
ld (hl),pattern
dec bc
ld a,b
or c
jr nz, loop
ENDMSi il n'y a pas de paramètres à passer à la macro, il n'est pas utile de passer (void) comme cela se faisait avec RASM.
Pour les boucles, même principe, et surtout une hérésie que l'on ne retrouve plus ici, les compteurs commencent par 0!
REPT 8,index
ld hl,#C000+#800*index
ld (hl),1<<index
ENDRIl faut noter que si vous utilisez beaucoup les boucles, par exemple pour générer beaucoup de données (remplir un écran vidéo avec un motif par exemple), SJASM+ est moins performant que RASM, en terme de vitesse d’exécution. En effet comme SJASM+ procède en plusieurs passes, il déroule intégralement le code avant de l'assembler, ce qui peut générer beaucoup de lignes de code. Même les commentaires semblent dupliqués, ce qui alourdit d'autant le processus d'assemblage. A manier avec précaution donc, sous peine de ralentissements, dans certains cas extrêmes. Mais heureusement, il s'avere que l'interpréteur LUA intégré est tres rapide, donc au besoin, il suffira de remplacer des blocs REPEAT par des blocs LUA, avec des boucles FOR. Nous reviendrons la dessus ultérieurement.
Les modules ont une syntaxe similaire, et n'ont pas de contrainte particulières, comme le fait de se référencer ou d’être imbriqués:
MODULE mymodule
lab1: ; mymodule.lab1
ld hl,@lab1 ; global lab1
ld hl,@lab2 ; global lab2
ld hl,lab2 ; mymodule.lab2
lab2: ; mymodule.lab2
ld hl,lab1 ; mymodule.lab1
ld hl,another_module.lab1 ; another_module.lab1
ld hl,nested.lab1 ; mymodule.nested.lab1
MODULE nested
lab1: ret ; mymodule.nested.lab1
ENDMODULE
ENDMODULE
MODULE another_module
lab1: ret ; another_module.lab1
@lab2: ret ; global label lab2
ENDMODULE
lab1: ret ; global label lab1
A noter l'usage de @ qui permet de définir ou référencer des labels 'globaux'.
Les exports
Cette partie va concerner des aspects spécifiques à l'architecture matérielle pour la quelle on va vouloir produire du code. En particulier pour exporter dans des formats propres aux émulateurs, comme les snapshots (SNA), tapes (TAP) et disks (DSK).
Une souplesse de SJASM+ sur ce point, c'est qu'il est possible d'exporter des fichiers à différents endroits du code source, voire meme de changer d'architecture au cours de l'assemblage.
Il faut commencer par définir l'architecture avec l'instruction DEVICE, et ensuite d'utiliser une fonction d'export:
DEVICE ZXSPECTRUM128
StartProg:
...
SAVESNA "snapshotname.sna", StartProg
Pour les Amstrad CPCs, il existe les architectures AMSTRADCPC464 et AMSTRADCPC6128:
DEVICE AMSTRADCPC464
ORG #1000
StartProg:
...
SAVECPCSNA "snapshotname.sna", StartProg
Il n'y a pas de directive RUN, le point d'entrée est passé directement à la directive SAVESNA
Les expressions
Les expressions arithmétiques sont similaires à RASM, mais certaines opérations arithmétiques, comme les exponentielles, les fonctions sinus et cosinus ne sont pas disponibles. En effet, le core gère du calcul 32 bits en entiers, à la différence de RASM qui effectue tout en flottant (ce qui nécessite d'être vigilant dans certains cas).
Pour palier à cela, SJASM+ intègre un bridge vers LUA, ce qui fait plus que compenser ces manques, car il permet aussi d'étendre le langage, et ce, sans pour autant alourdir inutilement le core de l'assembleur. On pourra alors bénéficier d'un véritable langage, pour générer du code, des patterns (par exemple générer des sprites en mode 1, décalés d'un pixel horizontalement) , des data, ou même rajouter des fonctions d'export (par exemple pour produire des snapshots pour un émulateur), etc.
Ce sujet sera traité dans un autre article, car il dépasse le sujet de la migration vers SJASM+. Mais c'est important de souligner l'existence d'une telle intégration, puisque elle permet d'avoir accès à toute la souplesse d'un véritable langage de script, avec des variables, des expressions arithmétiques poussées et bien plus encore.
Les aides au développement
Fonction simple mais fort pratique, il est possible d'envoyer du texte vers la console, avec l'instruction DISPLAY. (Si on utilise LUA, on a aussi accès à une instructionprint).
Des variables accessibles depuis le langages ont définies, en particulier la date (et l'heure) d'assemblage, ce qui peut aider à s'y retrouver dans ses releases!
Enfin, coté intégration dans des IDEs, comme VS codium, la plupart des plugins sont compatibles avec la syntaxe de SJASM, comme Z80-Macroasm ou ASM Code Lens:
mborikmaziactheNestruoJe suis tombé sur cette vidéo, dans laquelle on voit que la touche COPY semble se comporter de facon étonnante, car elle ne saurait pas faire la différence entre un bon caractère et un mauvais caractere à l'écran.
Pour
]]>Je suis tombé sur cette vidéo, dans laquelle on voit que la touche COPY semble se comporter de facon étonnante, car elle ne saurait pas faire la différence entre un bon caractère et un mauvais caractere à l'écran.
Pour rappel, la fonction Copy permettait de dédoubler le curseur à l'écran, de placer ce seconde curseur n'importe ou à l'écran et de recopier ce qu'il se trouve à l'écran à cet endroit, l'emplacement du premier curseur, à partir du moment ou il s'agit d'un caractère reconnu par le firmware. Si on tentant de recopier un bout de dessin fait à l'aide de PLOT et de DRAW, on avait droit à un beep de mécontentement.
Mais alors comment expliquer ce qui est décrit comme un phénomène sidérant dans la vidéo? Rien de plus simple, il suffit d'aller jeter un œil dans la ROM! Nous allons nous baser sur une version disponible en ligne, il en existe plusieurs, celle ci est scindée en plusieurs fichiers ce qui est plus pratique:
Bread80Parmi la liste des fichiers, le premier qui attire notre regard est LineEditor.asm. Une recherche du mot 'COPY' nous mène directement à la ligne 637:
;; COPY key pressed
COPY_key_pressed:
push bc
push hl
call TXT_GET_CURSOR
ex de,hl
call get_copy_cursor_position
jr nz,_copy_key_pressed_12
ld a,b
or c
jr nz,_copy_key_pressed_25
call TXT_GET_CURSOR
ld (copy_cursor_rel_to_origin),hl
jr _copy_key_pressed_14
;;--------------------------------------------------------------------
_copy_key_pressed_12:
call TXT_SET_CURSOR
call TXT_PLACE_CURSOR
_copy_key_pressed_14:
call TXT_RD_CHAR
push af
ex de,hl
call TXT_SET_CURSOR
ld hl,(copy_cursor_rel_to_origin)
inc h
call TXT_VALIDATE
jr nc,_copy_key_pressed_23
ld (copy_cursor_rel_to_origin),hl
_copy_key_pressed_23: ;
call _shift_key__left_cursor_pressed_21
pop af
_copy_key_pressed_25:
pop hl
pop bc
jp c,edit_for_key_13
jp edit_sound_bleeperPour réaliser une analyse rapide, on pourra consulter la table des indirections du pack text (préfixé par TXT), que l'on peut retrouver ici. En particulier:
| ADDR | CODE | Description |
|---|---|---|
| &BB4E | TXT_INITIALISE | Initialise the Text VDU |
| &BB51 | TXT_RESET | Reset the Text VDU |
| &BB5A | TXT_OUTPUT | Output a character or control code to the Text VDU |
| &BB5D | TXT_WR_CHAR | Write a character onto the screen |
| &BB60 | TXT_RD_CHAR | Read a character from the screen |
| &BB6F | TXT_SET_COLUMN | Set cursor horizontal position |
| &BB72 | TXT_SET_ROW | Set cursor vertical position |
| &BB75 | TXT_SET_CURSOR | Set cursor position |
| &BB78 | TXT_GET_CURSOR | Ask current cursor position |
| &BB87 | TXT_VALIDATE | Check if a cursor position is within a window |
| &BB8A | TXT_PLACE_CURSOR | Put a cursor blob on the screen |
| &BB8D | TXT_REMOVE_CURSOR | Take a cursor blob off the screen |
| &BBA5 | TXT_GET_MATRIX | Get the address of a character matrix |
| &BBA8 | TXT_SET_MATRIX | Set a character matrix |
Donc Après une analyse rapide, on comprend que l'appui de la touche copie provoque la récupération de la position des 2 curseurs ( TXT_GET_CURSOR ) suivi de l'appel a TXT_RD_CHAR, suivi d'une validation ( TXT_VALIDATE ), qui si elle échoue provoque l'émission d'un son (edit_sound_bleeper) . Cette validation est essentielle, car la fonction de recopie à l'écran est utilisée pour écrire du texte qui sera analysé par l'interpréteur basic. Il est hors de question de copier des caracteres inexistants!
Le vecteur &BB60
Ce TXT_RD_CHAR semble donc être la clé de notre énigme. Une rapide recherche dans Clefs Pour Amstrad nous donne:

Bingo! C'est donc cette routine qui serait à l'origine du mystère présenté dans la vidéo. Allons voir le code de TXT_RD_CHAR, cette fois ci dans le fichier text.asm, à la ligne 720:
TXT_RD_CHAR:
push hl
push de
push bc
call scroll_window
call TXT_UNWRITE
push af
call TXT_DRAW_CURSOR
pop af
pop bc
pop de
pop hl
ret
Rien de particulier, si ce n'est l'appel à TXT_UNWRITE, qui contient cette boucle:
ld c,$00
_ind_txt_unwrite_21:
ld a,c
call TXT_GET_MATRIX
ld de,RAM_b738
ld b,$08
_ind_txt_unwrite_25:
ld a,(de)
cp (hl)
jr nz,_ind_txt_unwrite_3
inc hl
inc de
djnz _ind_txt_unwrite_25
ld a,c
cp $8f
scf
ret
_ind_txt_unwrite_35:
inc c
jr nz,_ind_txt_unwrite_21;
xor a
ret
Cette boucle compare un à un les caractères de la fonte avec le contenu de la RAM en &B738. TXT_GET_MATRIX permet de récupérer le caractère. La zone en &B738 est utilisée par une autre fonction du firmware, cette fois dans le pack Screen, SCR_REPACK (&BC56). Elle est appelée au début de TXT_UNWRITE.
En effet, il y a la une subtilité gérée par le firmware, c'est qu'en fonction du mode écran, un même caractère n'occupera pas le même nombre d'octets en RAM. Il faut donc procéder a la transformation de la ce qu'il y a à l'écran sous forme standardisée. C'est exactement le rôle de SCR_REPACK:
&B738 : Compress a character matrix to the standard form
J'invite le lecteur à aller regarder le code de SCR_REPACK à la ligne 1146 du fichier Screen.asm en guise de récréation. Nous allons ici nous contenter de regarder le contenu de a RAM en &B738, après avoir entré le caractère A dans l'éditeur Basic, selon les modes:



Il faut aussi se rendre compte que la matrice utilisée pour la comparaison tient aussi compte du fait qu'elle peut avoir été redéfinie par l'utilisateur (avec la fonction SYMBOL duBasic).
Conclusion
Il est remarquable de constater la encore la grande sophistication du firmware utilisé dans l'Amstrad. L'absence d'un véritable mode texte sur CPC a forcé les ingénieurs qui ont conçu cette machine, de mettre en œuvre toute une stratégie pour réaliser cette fonction de recopie à l'écran. Derrière cette fonction, il faut en effet récupérer les données placées sous le curseur, le convertir selon les modes utilisés, et aller comparer les caractères un a un avec la fonte système (voire la fonte redéfinie par l'utilisateur avec SYMBOL), et le cas échéant recopier le caractère.
Liens
Bread80Richard-LloydAujourd’hui on va jouer autour d’une api qui permet de créer des interactions avec le chat d’une chaîne twitch. On ne parlera pas ici de piloter votre application (typiquement un jeu) à partir de commandes lancées dans un
]]>Aujourd’hui on va jouer autour d’une api qui permet de créer des interactions avec le chat d’une chaîne twitch. On ne parlera pas ici de piloter votre application (typiquement un jeu) à partir de commandes lancées dans un jeu, mais plutôt de créer une interaction conversationnelle directement dans le chat twitch.
Il existe de nombreux robots qui permettent de créer des interactions[1-3] , mais dès que l’on souhaite sortir des sentiers battus, il devient rapidement nécessaire de développer un peu. Heureusement les prérequis sont très réduits, l’API en question est simple, efficace et va à l’essentiel. Il existe de nombreux tutoriels sur internet, que ce soit en node ou en python (ou autre), en premier lieu la doc officielle twitch qu’il faut impérativement lire (elle est très courte)
Ici nous allons nous focaliser sur un exemple concret en nodejs. La première chose est d’avoir un compte twitch pour le bot. Vous pouvez utiliser votre compte personnel, au moins dans un premier temps, mais ce n’est pas idéal. En effet il n’est pas possible d’utiliser un autre pseudo que le compte auquel il est rattaché, donc le bot parlera au même titre que vous, ce qui peut créer des confusions.
Une fois le compte créé, il faut générer un token d’authentification, ce qui va permettre d’identifier le bot au niveau de votre application. Il suffit d’aller sur cette page et de demander un token. Ce token est bien entendu privé, copiez le dans un coin de votre disque dur, et ne le partagez en aucun cas. On a donc pour le moment:
- BOT_USERNAME : c’est le nom du compte/de la chaîne
- OAUTH_TOKEN: le token récupéré plus haut
La première chose a faire est d’installer le package tmi.js:
npm init
npm install -j tmi.js
Attention: il existe un package ‘tmi‘ qui n’a rien à voir, il faut bien utiliser le package tmi.js !
Première application
Notre première application va être très simple consister a se connecter sur une ou plusieurs chaînes, et de répondre quand on lui parle (avec @). Cela va nous permettre de voir comment se connecter au chat, et comment gérer les messages.
Avant de se pencher sur le code, précisons que nous l’exécuterons en lui passant les variables suivantes CHANNEL_NAME et CHANNEL_PASSWORD avec le contenu des données récupérées plus haut.
CHANNEL_NAME= CHANNEL_PASSWORD= node ./bot.jsOn va commencer par importer le package tmi.js, récupérer les variables d’environnement, construire un objet qui va nous servir à créer la connexion avec le chat. On utilise process.env pour récupérer les variables.
const tmi = require('tmi.js'); // API Twitch
// On récupere les variables passées
let botname = process.env.CHANNEL_NAME;
let botpassword = process.env.CHANNEL_PASSWORD;
// Si elles n'existent pas, on quitte
if (!botname || !botpassword) {
console.error('No CHANNEL_NAME or CHANNEL_PASSWORD environment variable found. Exiting.');
process.exit(-1);
}
// On ajoute le préfixe oauth:
botpassword = 'oauth:' + botpassword;
Et on construit l’objet opts, qui contient les informations de connexion, la liste des chaines auxquelles de connecter, ainsi qu’une option pour que le bot se reconnecte automatique en cas de déconnexion
// On construit l'objet qui contient les parametres de connexion
const opts = {
identity: {
username: botname,
password: botpassword
},
channels: [
botname
//on peut ajouter d'autres chaines
],
// Automatic reconnection
connection: { reconnect: true }
};Voila, maintenant on est prêt à se connecter! On crée un objet client à l’aode de notre objet opts. On lui associe deux gestionnaires d’évenement (dont nous verrons la définition plus bas), et on se connecte!
// Création d'un client
const client = new tmi.client(opts);
// Gestionnaire d'évenements
client.on('message', onMessageHandler);
client.on('connected', onConnectedHandler);
// Connexion!
client.connect();En ce qui concerne le handler ‘connected‘, on va se contenter d’un log en console:
// Fonction appellée a chaque fois que la connexion est établie
function onConnectedHandler(addr, port) {
console.log(`* Connected to ${addr}:${port}`);
}Maintenant que tout est en place, il nous reste à rentrer dans le vif du sujet, à savoir écrire la fonction qui va recevoir tous les messages qui passent sur le chat des chaines sur lesquelles le bot est connecté.
La fonction onMessageHandler reçoit 4 paramètres:
- target: le nome de la chaine ou a été envoyé le message.
- context: les informations sur l’utilisateur qui a envoyé le message. On pourra récupérer son nom, ainsi que son statut par rapport a la chaine (abonné, modérateur, …)
- msg: le texte du message
- self: indique si le message a été émis par le bot lui même. Sert pour ignorer ces messages.
Notre fonction pour répondre si quelqu’un envoie un message au bot ressemblera à cela:
function onMessageHandler(target, context, msg, self) {
try {
// Ignore les messages du bot
if (self) { return; }
// On vérifie si le nom du bot est dans le message
if (msg.indexOf('@'+botname)>=0) {
// Si oui on répond a l'utilisateur
client.say(target, 'Hello ' + context['display-name']);
// on log le contexte pour voir son contenu
console.debug(context);
}
}
catch (e) {
console.error(e.stack);
}C’est donc assez simple, si le nom du bot apparait dans le message, le bot répondra à l’utilisateur. Pour cela, on utilise la fonction say du client, qui prend le nom de la chaine en premier paramètre et le texte à envoyer sur le second.. Il est en effet judicieux de répondre sur la chaine où l’on a reçu le message ? . Pour répondre à l’utilisateur, on utilise le champ display-name de la variable contexte. On en profite pour loguer le contenu de la variable context pour voir les différentes valeurs qu’elle peut contenir.
Seconde Application: un bot traducteur!
Maintenant que nous avons vu les principes de base, allons un peu plus loin, avec une seconde application, un peu plus utile. Elle a déjà servi comme point de départ pour un bot plus sophistiqué (The Tangerine Bot) mais aussi pour quelques chaines twitch (speakeazybot par exemple).
Le code source de ce bot est disponible ici et se base sur l’utilisation de google translate pour la traduction. Il existe d’autres moteurs de traductions comme Yandex ou DeepL, j’ai choisi google translate car il propose une version gratuite, qui permet de tester le principe. Google comme Yandex ou DeepL proposent des versions payantes, qui sont de qualité sensiblement meilleure et avec beaucoup moins de limitation sur le nombre de transactions. A noter que Yandex est très performant pour les traductions depuis et vers le russe, et DeepL s’en sort très bien avec le japonais!
Pour commenter on ajoute le paquet googletrans:
npm install -j googletransAu niveau du code, on importe le paquet:
// API Google Translate
const gtrans = require('googletrans').default;Ensuite on se dote d’un tableau avec les commandes que l’on va vouloir ajouter. Le principe sera d’avoir une commande par langue. Par exemple !de permettra de traduire un texte en allemand. L’API de traduction se chargera de détecter la langue source et de la traduire dans la langue cible.
const tr_lang = {
'de': ['de', 'sagt'],
'en': ['en', 'says'],
'fr': ['fr', 'dit'],
'pt': ['pt', 'disse'],
};Maintenant il nous reste a répondre au cas ou l’on détecte l’une des commandes !de !en !fr ou !pr, en ajoutant dans la fonction onMessageHandler:
// Si le message ne commence pas pas ! on ne fait rien
if (msg[0] != '!') return;
// On récupere la commande
let cmd = msg.split(' ')[0].substring(1).toLowerCase();
// Est ce l'une des commandes de traduction?
if (cmd in tr_lang) {
let ll = tr_lang[cmd];
let txt = tMsg.substring(1 + cmd.length);
// Traduction
gtrans(txt, { to: ll[0] }).then(res => {
// Construit le message de réponse
let answer=context['display-name']+' '+ll[1]+': '+res.text;
client.say(target, answer);
}).catch(err => {
console.error('Translation Error:', err);
})
return;
}Lorsqu’une commande est interceptée, l’API de traduction est appelée, et le résultat, asynchrone est récupéré dans la variable res, si tout s’est bien passé. Ensuite, le message de réponse est construit et envoyé en guise de réponse. Par exemple:
Conclusion
Nous venons de faire nos premiers pas dans le monde des bots irc/twitch. Il y a plein d’applications à imaginer! Des applications créatives, qui changent des bots classiques, et surtout des bots qui polluent les chat, ou qui se contentent d’écouter les conversations, de les stocker on ne sait ou, pour en faire on ne sait quoi…
Dans les prochaines parties, nous aborderons la description de certains aspects d’un bot un peu plus sophistiqué que j’ai créé pour une chaîne musicale sur twitch, le Tangerine Bot! Il s’agira de stocker des informations en base pour rendre le comportement du bot plus riche et d’avantage adapté à chaque utilisateur.
Liens
- [1] streamelements – https://streamelements.com/
- [2] streamlabs – https://streamlabs.com/
- [3] buttsbot – https://www.twitch.tv/buttsbot
- [4] doc officielle twitch – https://dev.twitch.tv/docs/irc
- [4] Page de création du token: https://twitchapps.com/tmi/
- [4] tmi.js – Package JavaScript : https://tmijs.com/
- [5] https://github.com/sikorama/twitch_translate_bot
- [6] Google Translate: https://www.npmjs.com/package/googletrans
- [7] Yandex : https://translate.yandex.com/
- [8] DeepL: https://www.deepl.com/translator
Dans la démo ‘Unique Megademo’ de N.W.C., sortie en 1997 , la partie ‘4 Sins’, impressionne par le fait qu’il y ait 4 scrolltexts sinusoidaux simultanément à l’écran, ce qui semble a première vue
]]>
Dans la démo ‘Unique Megademo’ de N.W.C., sortie en 1997 , la partie ‘4 Sins’, impressionne par le fait qu’il y ait 4 scrolltexts sinusoidaux simultanément à l’écran, ce qui semble a première vue bien difficile a loger en terme de temps machine. Nous allons voir ici qu’une utilisation astucieuse de la palette de couleur, permet de réaliser cela

La premiere chose que l’on remarque dans cette partie, c’est que les 4 scrollings suivent exactement la meme trajectoire, ile peuvent totalement se supperposer, et c’est bien sur la que réside la clé de la compréhension de cet effet. De plus chaque scrolling est monochrome.
Regardons la composition de l’écran: Il est en mode 0 (donc on a 16 couleurs a notre disposition) et il se décompose en 4 écrans, gràce a des ruptures. Ces ruptures sont réalisées en fixant le Registre 9 du CRTC à 1, et le registre 4 est fixé à la valeur standard de #26. Pour rappel le registre 9 controle le nombre de scanlines par ‘bloc texte’, et le registre 4 indique la hauteur d’un écran, exprimé en blocs texte. Ainsi chaque écran fait (R9+1)*(R4+1) lignes, soit 2*39 = 78 lignes, dont 42 lignes visibles, si on exclue la zone ‘border’
Les 4 écrans sont séparés par des zones noires, qui correspondent au blanking video (le Registre 7 est fixé à #18)
Deuxieme chose que l’on constate, c’est que les 4 écrans ont le meme offset vidéo! Cet offset alterne entre #4000 et #c000 (R12=#10 ou #30) d’une trame à l’autre, de facon à avoir un scrolling à l’octet, ainsi que du double buffering. Le double buffering est necessaire pour eviter tout effet de ‘flickering’ le temps de redessiner les scrolltexts… ou plutot le scroll text!
En effet, si on se penche sur les palettes utilisées dans les 4 zones de l’écran, on observe que les couleurs suivantes sont utilisées:




Il s’agit donc d’une utilisation d’une technique de masquage pour superposer les 4 textes au meme endroit dans la mémoire vidéo. Un bit (parmi les 4 disponibles) est dédié a chaque scrolling:
- Le bit 2 pour le premier écran (blanc sur fond mauve),
- Le bit 1 pour le second (blanc sur fond rouge),
- Le bit 0 pour le troisième, (bleu clari sur fond violet)
- Le bit 3 pour le dernier (noir sur fond jaune).
Si on applique une palette ou chaque couleur est différente, on obtient une image qui permet de bien se rendre compte de la superposition:

Toute l’astuce de cette partie consiste donc a combiner les 4 textes lors du rendu graphique du scroll sinus. Bien sur, le code du scrolling lui même nécessite une bonne dose d’optimisation, à la fois pour l’animation sinus, mais aussi le calcul efficace de la superposition des 4 textes.
Notons au passage l’utilisation de 4 fontes différentes pour nous embobiner!
Liens
- Le fichier DSK sur CPC Power: https://www.cpc-power.com/index.php?page=detail&num=8307
Résumé des Techniques employées:
- Scrolling Sinus à l’octet
- Ruptures
- Masquage de bits pour la superposition
- Double Buffering
Voici une mise a jour d’un billet précédent, où l’on expliquait comment jouer un soundtrack avec Arkos tracker. Dans la seconde version d’Arkos Tracker (AT2), il existe de nombreux formats de soundtracks, qui sont détaillés
]]>Voici une mise a jour d’un billet précédent, où l’on expliquait comment jouer un soundtrack avec Arkos tracker. Dans la seconde version d’Arkos Tracker (AT2), il existe de nombreux formats de soundtracks, qui sont détaillés dans sa documentation intégrée, qui est très complète. Il y a même un article, en anglais, écrit pas Targhan himself, qui décrit la même chose que le présent billet. Il est possible de jouer des musiques sur de nombreuses architectures. Ce billet est simplement la pour démarrer rapidement, avec pour commencer un exemple simple, et dans un second temps une description des différents formats disponibles, avec leur avantage et inconvénients.
Exemple simple
Dans cet exemple, nous allons utiliser le format le plus simple et le plus compact, le format Lightweight. Les exemples et la documentation se trouvent dans le répertoire player/playerLightweight. Vous pourrez retrouver des exemples ici .
Une fois votre soundtrack créé, il faut l’exporter au format AKL. La façon la plus efficace est de générer un fichier sous forme de source et non en binaire, de façon à rester indépendamment de l’adresse ou l’on souhaite loger le fichier. De plus, il faudra prendre soin sélectionner l’option pour générer le fichier de configuration:
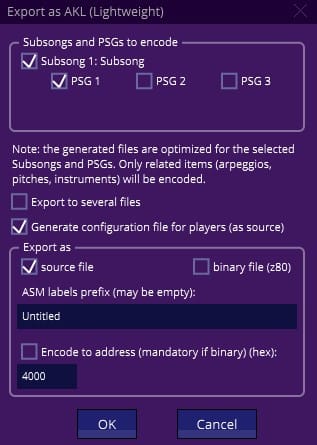
Ensuite il suffit d’adapter l’exemple fourni (PlayerLightweight.asm) avec le fichier que l’on a généré. Si on réduit le source au strict minimum:
org #1000
di ; Désactive les ITs systeme
ld hl,#c9fb ; Ei : RET en #38
ld (#38),hl
ld sp,#38
ld hl,Music ; Initialisation
xor a ; Subsong #0.
call PLY_LW_Init
Mainloop:
; Attente VBL
ld b,#f5
Sync:
in a,(c)
rra
jr nc,Sync
; Attente première interruption
ei
nop
halt
di
call PLY_LW_Play ; Jouer la musique
jr MainLoop
Music:
; La configuration n'est pas obligatoire, mais elle permet
; de réduire la taille du binaire produit (ici 1.6K au lieu de 1.8K)
include "./barbapapa_lw_playerconfig.asm"
; Soundtrack exporté
include "./barbapapa_lw.asm"
Player:
include "./PlayerLightweight.asm"Dans cet exemple, les 2 fichiers exportés sont barbapapa_lw.asm et barbapapa_lw_playerconfig.asm. Le second fichier est un fichier de configuration, qui n’est pas obligatoire, mais il permet de réduire (dans cet exemple) la taille du binaire produit de 1.8K a 1.6K.
L’attente avec le Halt permet de s’assurer que la boucle dure suffisamment longtemps pour que l’attente VBL fonctionne. Elle n’est pas obligatoire, en particulier quand il y aura plus de code (et dont de temps machine utilisé) dans la boucle principale.
Cliquez ici pour lancer l’émulateur intégré et visualiser le résultat, directement depuis votre navigateur.Jouer plusieurs soundtracks
Pour gérer plusieurs soundtrack, il faudra générer un fichier source pour chaque soundtrack, en prenant soin de paramétrer un préfixe différent à chaque fois. On pourra ensuite inclure les fichiers dans le source initial de la sorte:
Song1:
include "./song1_lw_playerconfig.asm"
include "./song1_lw.asm"
Song2:
include "./song2_lw_playerconfig.asm"
include "./song2_lw.asm" Et initialiser l’une ou l’autre, par exemple la seconde:
ld hl,Song2
xor a
call PLY_LW_InitPour passer d’une soundtrack à une autre, il faudra arrêter la lecture (en appelant PLY_LW_Stop) et initialiser la nouvelle:
call PLY_LW_Stop
ld hl,Song1
xor a
call PLY_LW_InitJouer des FX
Il est possible de jouer des sons par exemple pour agrémenter un jeu. Les sons peuvent être joués sur le channel de son choix, éventuellement par dessus une musique en train de se jouer.
Il faut commencer par déclarant le symbole PLY_LW_MANAGE_SOUND_EFFECTSavant l’inclusion du player:
Player:
PLY_LW_MANAGE_SOUND_EFFECTS EQU 1
include "./PlayerLightweight.asm"Notez que l’utilisation de FX nécessitera la présence du fichier PlayerLightweight_SoundEffects.asm. Ensuite il faut inclure le fichier FX généré précédemment:
SoundEffects:
include "../mySoundEffects.asm"Ensuite on procède à l’initialisation des effets:
ld hl,SoundEffects
call PLY_LW_InitSoundEffectsEnfin, il est possible de jouer le son sur un canal donné, en passant son numéro:
ld c,0 ;Channel 1
ld a,0 ;Numero du FX
ld b,0 ;Volume max
call PLY_LW_PlaySoundEffectIl est possible d’arrêter le son à tout moment :
ld a,0 ; Channel 1
call PLY_LW_StopSoundEffectFromChannelA noter qu’il est possible de se contenter d’utiliser un player restreint aux FX uniquement, si l’on souhaite jouer des sons et pas de soundtrack (PlayerSoundEffects.asm)
Tour d’horizon des formats et players
Les principaux formats disponibles avec AT2 sont les suivants
- Le format « lightweight » (AKL) utilisé dans l’exemple précédent. Il permet de lire la plupart des fichiers que l’on pourra produire avec AT2, sur CPC, MSX, Spectrum ou encore sharpMZ700. Il a l’avantage de produire des fichiers de taille réduite (soundtrack et player). Par contre il n’est pas le plus optimum en terme de temps CPU utilisé pour jouer, et nécessite de désactiver les interruptions pendant son utilisation.
- Le format ‘Minimaliste‘ (AKM): C’est un format encore plus compact que le format lightweight, en retirant certains possibilités du format lightweight, comme certains sons hardware. Il est idéal pour une production 4K par exemple.
- Le format ‘Générique’ (AKG) qui permet d’utiliser toutes les possibilités offertes par AT2, et est plus efficace que le format AKL en terme de CPU (mais il prend plus de place en mémoire)
- Le format ‘Sound effect’, qui peut être utilisé pour jouer des sons sur un seul channel, soit par dessus une mélodie, soit de façon totalement indépendante, grâce à un player dédié
A noter qu’il existe aussi un format ‘MOD’ qui permet de jouer des samples. (un exemple ici)
Le format AKL est indiqué comme ‘plutôt’ obsolète dans la documentation d’Arkos Tracker, car d’un coté le générique est plus versatile, et le minimaliste est plus compact. Il fonctionne cependant parfaitement, et il n’y a aucune difficulté à passe à un autre format. Il suffit de choisir la bonne option d’export dans AT2, et d’inclure le player correspondant.
Liens
- Article de Targhan: http://www.julien-nevo.com/arkostracker/index.php/using-a-song-in-production-using-rasm/
- Site officielle d’Arkos Tracker 2: http://www.julien-nevo.com/arkostracker/
- Page Z80-Live: https://z80live.sikorama.fr
VScode (ou VScodium) est un éditeur de texte orienté code, multi plateforme (linux, windows, mac OS) et qui se situe dans la lignée d’atom, notepad++ ou encore sublime text. Ce sont des éditeurs plutôt légers et très
]]>
VScode (ou VScodium) est un éditeur de texte orienté code, multi plateforme (linux, windows, mac OS) et qui se situe dans la lignée d’atom, notepad++ ou encore sublime text. Ce sont des éditeurs plutôt légers et très modulaires, grâce à leur système de plugins. Pour l’installer, il suffit de suivre les instructions ici.
Je vais décrire ici la configuration de vscode pour développer avec votre assembleur préféré pour CPC, que ce soir SJasm+, Rasm ou encore UZ80. Nous verrons comment ajouter des commandes, et nous pencherons sur l’usage de deux plugins dédiés à simplifier le développement en assembleur z80. Le contenu de cet article est basé sur des échanges avec Ivan Duchaufour (alias gurneyh), qui a apporté sa contribution aux deux plugins dont il va être question.
Pour commencer, voyons comment ajouter des commandes pour exécuter RASM sur votre propre projet.
Commande build
Vscode permet d’ajouter très simplement des commandes personnalisées, pour chaque projet que l’on crée avec. Pour cela, il suffit de créer (ou d’éditer) le fichier task.json et d’y ajouter un objet dans le tableau tasks, qui ressemble a cela:
{
"version": "2.0.0",
"tasks": [
{
"label": "build-rasm",
"group" : "build",
"command": "rasm",
"args": [
"./main.asm",
"-o",
"test"
],
"problemMatcher": "$errmatcher-rasm"
}
]
}Exécuter cette tache revient à exécuter la commande
rasm ./main.asm -o testVous pouvez adapter cette tache, en modifiant le chemin d’accès à rasm si nécessaire (command), et modifier les paramètres passés à RASM (args). Le paramètre ‘problemMatcher‘ servira dans la suite, pour que les erreurs et warnings renvoyés par RASM soient récupérés par le plugin Macro Assembler (si le plugin n’est pas installé, il faudra commenter cette ligne). A la fin de l’article vous retrouverez d’autres exemples de tâches.
Comme la tâche fait partie du groupe ‘build’, le raccourci CTRL+SHIFT+B permet d’éxécuter directement la commande.
Installation des plugins
A noter que dès que vous ouvrez une fichier .asm, vscode suggère l’utilisation de plugins (appelées extension). Il est aussi possible de chercher avec le mot clef ‘Z80’ dans le menu extension. Parmi la liste proposée, il faudra choisir Z80 Macro-Assembler et Z80 Assembly meter. Le premier apporte la coloration syntaxique et la gestions des erreurs, tandis que le second permet de calculer rapidement la taille ainsi que le temps d’exécution (en cycles ou en micro secondes) d’un bloc de code.
Gestion des erreurs
Considérons le code suivant: (spoiler: il est truffé d’erreurs):
org #8000
ld u, "a"
call #fffff
loop:
jp .loopSi on execute notre commande build-rasm sur ce fichier, on obtiendra le résultat suivant:
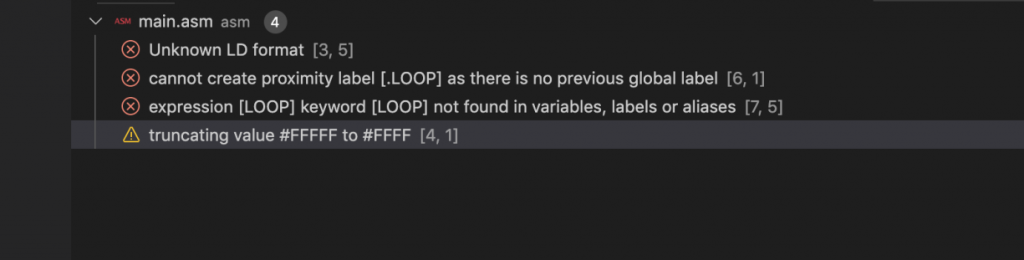
Timing des instructions
Si l’on sélectionne une section du code, la barre d’information en base de la fenêtre indique la taille en octet et le nombre de cycles du bloc. Quelques informations supplémentaires apparaissent en survolant cette zone:
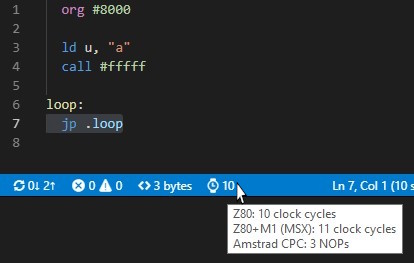
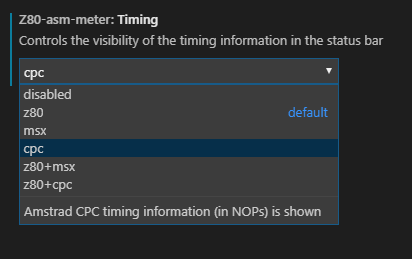
Par défaut, le plugin indique le nombre de cycles, mais il est possible dans les options de sélectionner le timing pour le CPC (parmi d’autres).
Build avancée
Lorsqu’un projet grossi, il devient pratique d’utiliser un script bash ou un makefile pour builder le projet.
Imaginons que l’on souhaite exécuter un script bash situé à la racine de notre projet, on peut ajouter une autre tâche de build, le fichier task.json deviendrait alors:
{
"version": "2.0.0",
"tasks": [
{
"label": "build-rasm",
"group" : "build",
"command": "rasm",
"args": [
"./main.asm",
"-o",
"test"
],
"problemMatcher": "$errmatcher-rasm"
},
{
"label": "build",
"group" : "build",
"command": "./build.sh",
"problemMatcher": "$errmatcher-rasm"
}
]
}On peut également continuer à utiliser le problemMatcher spécifique à RASM dans ce cas.
Si vous souhaitez créer une tache pour compiler le fichier actuellement ouvert, au lieu de main.asm il suffit de remplacer l’argument par « ${file}« :
"args": [
"${file}",
"-oa"
],L’option -oa permet d’utiliser le nom du fichier en entrée pour générer le fichier en sortie (RASM V.0115 ou supérieur requis).
Executer un émulateur
Toujours à l’aide des Tasks, il est possible par exemple, de créer une commande run qui exécutera l’émulateur de votre choix, pour y lancer directement le.dsk, .cpr ou .sna voulu… mais ce sera l’objet d’un autre article!
Quelques liens:
]]>Dans sa version de Juillet 2019, Arkos Tracker 2 (AT2) intègre le support du MIDI, en offrant la possibilité de connecter un périphérique MIDI (clavier maître par exemple), mais aussi et surtout d’importer des fichiers MIDI, ce qui offre
]]>
Dans sa version de Juillet 2019, Arkos Tracker 2 (AT2) intègre le support du MIDI, en offrant la possibilité de connecter un périphérique MIDI (clavier maître par exemple), mais aussi et surtout d’importer des fichiers MIDI, ce qui offre de nombreuses possibilités, en particulier si on utilise des logiciels d’édition comme Guitar Pro ou un arrangeur comme Band in a Box, (pour ne citer que ceux la). On peut donc s’attendre à un déferlement de nouvelles musiques sur CPC (ainsi que les autres architectures supportées par AT2), tant l’outil est efficace, mais il ne dispense pas pour autant de faire tout le travail de réduction des pistes (les ramener à 3 pour le CPC), ainsi que de remodeler les instruments pour rendre le son plus dynamique. Comme toujours, venez partager vos commentaires et vos transferts sur le forum!
Premier import
Au même titre que l’on peut ouvrir un fichier tracker, on peut dorénavant ouvrir un fichier midi directement depuis AT2, par le menu file/open song ou en glissant un fichier midi sur la fenêtre d’AT2. Apparaît alors un popup menu permettant de paramétrer l’import. Munissez vous donc de quelques fichiers MIDI, glanés sur le net, si vous n’en avez pas, quelques uns seront proposés dans la suite.
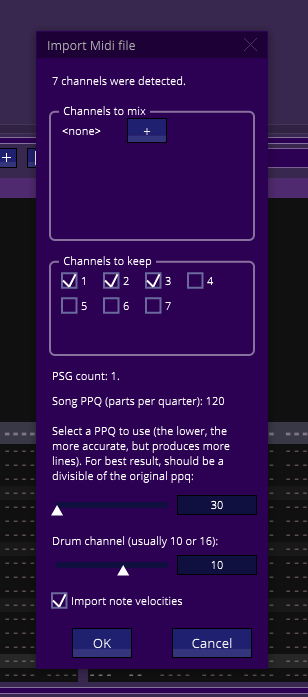
Le nombre de pistes est indiqué en premier lieu, ici 7, suivi de deux cadres, le premier servant à indiquer quelles pistes mixer, et le second permettant de sélectionner les pistes a importer. Le processeur sonore du CPC n’étant doté que de 3 voix, il n’est en principe pas possible d’utiliser plus de voix, mais AT2 gère l’utilisation de plusieurs PSGs. Ce qui permet d’avoir autant de voix que nécessaire, et simplifie le travail de composition. Pour une première écoute, il vaut mieux sélectionner toutes les pistes, quitte à recharger le fichier avec uniquement les voix qui nous intéressent.
Le paramètre PPQ permet de jouer sur la quantization des notes. Pour les morceaux où chaque note est bien calée sur les temps forts, ce paramètré peut être élevé. Pour ceux qui usent de syncopes, et de groove, bref des divisions un peu plus fines, il faudra proivilégiers un PPQ plus bas. A noter que plus la valeur est basse, plus le nombre de séquences va s’accroître, ce qui prendra plus de place mémoire.
Il n’est en général pas nécessaire de changer le paramètre ‘Drum Channel’, qui indique le canal dédié à la batterie. De même, on gardera la case ‘Import note velocities’ cochée, puisque c’est ainsi que l’on peut garder toutes les nuances du jeu et des attaques contenues dans le fichier MIDI.
L’importation peut prendre du temps, d’autant plus que le morceau est long, et qu’il y a de nombreuses pistes. Voici quelques exemples, d’importation brute, sans aucune retouche, avec le fichier midi utilisé pour l’import.
Claire de Lune – Debussy (2 pistes)
Chicken – Jaco Pastorius (9 pistes)
Mercy, Mercy Me (Marvin Gaye) (57 pistes)
Non seulement le tempo général du fichier midi est utilisé pour sélectionner la vitesse générale, mais les changement de tempo en cours de morceau sont aussi pris en compte. Par exemple dans ‘Clair de Lune’, on a la colonne ‘Speed’ qui est régulièrement modifiée:

Instruments générés
Des instruments sont crées automatiquement, les sonorités sont simples, et le panel est réduit, par exemple, que ce soit la trompette, une guitare électrique ou un piano électrique, le même instrument est affecté, avec un sont plutôt neutre, et une enveloppe qui diminue l’amplitude:
Malgré cela, les instruments affectés automatiquement permettent d’avoir une bonne idée de l’arrangement. Il va falloir les retravailler bien sûr, mais ils sont déja créés, prêts à être remodelés.
Des batteries
Pour les batteries, les instruments sont plutôt bons et variés, par exemple ici la grosse caisse et un charlet fermé:

La conversion des pistes de batteries est tout à fait performant, AT2 arrive à utiliser peu de pistes,et donne un son convaincant sans aucun réglage, en particulier du fait de l’importation de la vélocité. J’ai fait quelques essais, avec des batteries générées par Band-in-a-Box (un arrangeur), dans différents styles. A chaque fois, un seul canal audio n’est utilisé. Quelques exemples:
Samba:
Disco:
Electro:
Modern Jazz
Bien choisir son PPQ
Dans ce de dernier exemple, la batterie est dans un style plus moderne, sonne bien avec les paramètres d’importation par défaut: Mais si on double la précision (en passant le PPQ de 120/4=30 à 15) , on se rend compte que la batterie est plus fine encore. Le tempo est un peu plus lent, mais on y distingue des roulements que l’on n’avait pas précédemment:
Si on compare les pistes (a gauche PPQ=30, à droite PPQ=15), on peut voir que chaque note dans l’image de gauche a son équivalent dans la colonne de droite. La note #20 correspond a la #00, le #21, à la #02, etc. Les notes à droite sont deux fois plus espacées ce qui est logique vu qu’on a divisé PPQ par 2.
PPQ=30 
PPQ=15
Ceci dit, on voit que certaines notes présentes dans le second cas sont passées à la trappe avec PPQ=30. Par exemple ici, les notes en #27 et #28 sur la colonne de gauche correspondent aux notes #0E et #10 de la colonne de droite, et qu’en #0F, il y a une note qui ne peut pas avoir d’équivalent avec PPQ=30.
D’une manière générale, si un import avec les réglages par défaut ne sont pas convaincants au niveau du rythme, ou si des notes tout simplement perdues, il faudra réduire la valeur de PPQ
Réduction du nombre de pistes
La difficultés principale dans l’exploitation de fichiers au format midi, c’est qu’il va falloir tout faire loger sur 3 malheureuses pistes. Voici quelques techniques, à utiliser dans la mesure du possible:
- Éliminer toutes les pistes en doublon ou inutiles, ou vides.
- Fusionner la section rythmique (basse+batterie) en une seule piste: utiliser le canal de bruit pour marquer les basses ou inversement ajouter des notes dans les percussions.
- Les polyphonies et les accords peuvent être simulées par des arpèges au niveau des instruments. Il faudra créer autant d’instruments que nécessaire, chaque instrument correspondant à un accord. On utilisera la colonne « arp » du panel instrument pour ajouter autant de notes que nécessaire. Par exemple pour un accord majeur à 3 notes, on utilisera les intervalles +0, +4, +7 (fondamentale, tierce, quinte)
Mise en pratique
Je suis parti du thème de ‘Airwolf’ que j’ai trouvé sur internet. J’ai choisi ce morceau, non par sa qualité musicale intrinsèque, mais parce qu’en plus d’être connu, il est suffisamment court, il possède plus de 3 pistes, ce qui va nous forcer à le retravailler un minimum. Et puis il s’agit de montrer qu’on doit pouvoir faire mieux que la musique du jeu éponyme, qui était une vraie purge!
Voici le fichier MIDI original. A la première importation, il y a quelque chose qui cloche au niveau du rythme:
En le réimportant avec un tempo plus rapide, le rythme ternaire de l’accompagnement est bien mieux respecté. Seul souci, il faudrait pouvoir indiquer des l’importation que nos pistes ne font pas la longueur standard, ici la taille idéale serait de 40 ou 80, au lieu de 64.
Pour réduire le nombre de pistes, commençons par analyser les pistes:
- Piste 1: l’accompagnement, qui est continu et occupe toute la piste
- Piste 2: Basse
- Pistes 3,4,5: Mélodie
- Piste 8 et 9: Batterie
La méthode que l’on va appliquer est la suivante:
- On va conserver l’accompagnement qui est continu sur la première piste, en lui ajoutant un peu de noise de façon à renforcer le rythme. Cette piste évoque clairement par son rythme, le son des pales d’un hélicoptère.
- On va regrouper la basse et les 2 pistes de batterie.
- On va se concentrer sur la piste principale de la mélodie (le channel 3) et éventuellement essayer d’y insérer quelques notes intéressantes des pistes supplémentaires.
- Dans tous les cas, il va falloir donner un peu de nuance dans les instruments pour mieux les distinguer, et donner un peu d’expression
Voici le résultat final. Il faudrait encore retravailler la mélodie qui est un peu brute, et la fin qui sonne un peu brouillon, mais en l’état le résultat est déjà plus convaincant. Et surtout, il tourne sur un vrai CPC.!
Quelques explications
Pour la grosse claire, j’ai activé la boucle, sur la dernière ligne de l’instrument, en utilisant l’effet Arpège (Arp), 2 octaves en dessous (-#18), afin de sonner juste.
Ensuite j’ai utilisé les notes de la piste de basses pour les notes de grosse caisse. Sur l’image suivante, on voit comment on a regroupé les 3 pistes initiales (1 de basse et 2 de batteries) pour n’obtenir qu’une seule piste. Les notes de basse (A#, instrument #02) sont maintenant utilisés pour la grosse caisse (instrument #08) et la caisse claire (instrument #0A):

When you want to run a program on Amstrad CPC, the procedure is to use RUN command in BASIC. It will read data on the floppy disk (or cassette), transfer it to RAM and jump to the program’s entry point. Let’s write a small program that
]]>
When you want to run a program on Amstrad CPC, the procedure is to use RUN command in BASIC. It will read data on the floppy disk (or cassette), transfer it to RAM and jump to the program’s entry point. Let’s write a small program that can be executed with a simple LOAD command, meaning that simply transferring it to RAM will trigger its execution!
Loading with AMSDOS
AMSDOS cannot load a file to an area of the memory,that is too low. However, if a program is located in an area that is high, then the loading pushes through. It is important to note that the the stack initially points to &C000. Every time the CPC calls a function, it stores the return address into the stack (SP is then decreased by 2).
In other words, if Basic interpreter executes a CALL xxxx in &1234 , then &1237 is stored in the stack at &BFFE-&BFFF (SP = SP-2). When the function in xxxx ends, a RET is executed, which will then jump back to &1237 and put the stack back at &C000 (SP = SP + 2).
That being said, if we load a file located at &BEBE that goes up to &C000, and if the area to which the stack is currently pointing is filled by &BE bytes (&BE, &BE, &BE, &BE…. ), then the first RET that the system will encounter after loading will take the Z80A directly to &BEBE and thus run the loaded code!
Our program
di
ld bc,#7F10
ld hl,#4B5C
out (c),c
noend
out (c),h
nop
out (c),l
nop
jr noend
defs 140,#be ; #bfff-#bebe = 140If you attempt to SAVE this code from the CPC, tou’ll have to assemble it at another address (luckily our little piece of code is relocatable), save it, and modify the AMSdos header so that the program is located at the correct address.
Another solution consists of using RASM, which can directly generate this DSK with a correct Amsdos header for our file:
org #BEBE
start:
di
ld bc,#7F10
ld hl,#4B5C
out (c),c
noend:
out (c),h
nop
out (c),l
nop
jr noend
defs #bfff-$,#be
end:
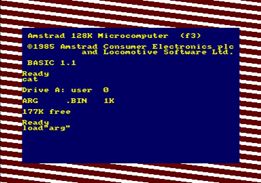
save 'arg.bin', start, end-start, DSK,'arg.dsk'Let’s see if it works:
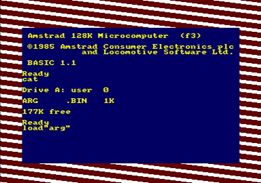
Something that has never been done, is a program launch using a simple CAT. I think it’s impossible,but who know?
]]>Pour inaugurer la section ‘archives’, voici un courrier daté du 31 Août 1992, que j’ai reçu de la part de Longshot. Il y décrit l’état déjà bien avancé de la compré
]]>
Pour inaugurer la section ‘archives’, voici un courrier daté du 31 Août 1992, que j’ai reçu de la part de Longshot. Il y décrit l’état déjà bien avancé de la compréhension de la rupture verticale, technique révélée pas la célèbre S&KOH , sortie en Novemlre. J’ai retranscrit ici le texte intégral de l’explication (avec une correction apportée par son auteur), car le texte est plutôt clair étant donné la complexité du sujet. J’ai refait les schémas pour une meilleure visibilité. Pour accéder au scan des courriers originaux, ainsi qu’à un espace de discussion, ca se passe sur le forum.
Je vois que tu as bien pigé la rupture ligne à ligne, et que tu ne fais pas comme beaucoup de monde qui veulent savoir ce qui est la RVI (l’adressage de plusieurs blocs) avant de maîtriser totalement la Rupture Horizontale (RH), qui est la rupture que tu as utilisé jusqu’alors.
Tu me demandes comment avoir plus de blocs (puisque tu t’es malheureusement aperçu que l’offset démarre toujours et seulement sur le premier bloc de 2048 octets soit 2048*4 pages : 8192 octets en ligne a ligne, ceci en supposant qu’on ne peut plus servir du reste, même en modifiant R9, puisque les premiers blocs servent à autre chose…)
Bref, la solution fût trouvée par Overflow à l’aide de techniques que je n’avais pas exploitées complètement: la Rupture Verticale. La Rupture Verticale avait pour but, à l’origine de couper l’écran en 2 (ou plus), pour changer de mode graphique (uniquement possible durant 1 HBL de au moins 2μs ) ou d’offset..
Ainsi, tout comme en RH, le R0 contient le nombre de μs sur une ligne, soit 63 (+1) = 64μs (sur tous les ordinateurs, puisque cette valeur dépend de la fréquence de balayage du moniteur.. 0.000064sec*312.5 = 0.02sec, soit 1/50ème, .. 50Hz!) . Si R0=31, alors le CRTC générera un split au milieu des 64μs de 2×32μs. La largeur de la bande HBL (qui ne compte pas dans les 64 μs mais est juste une zone noire en surimpression visuelle) est déterminée par R3. Cette zone noire correspond à peu près à R7 car elle a un rapport avec la synchro de l’image (synchro horizontale) et sa position est déterminée par R2..
Bref, il est nécessaire que la zone sync du moniteur (qui dure quelques μs) soit en parallèle avec celle du CRT pour que l’image soit stable horizontalement. (R3 dois être au moins à 7 dans le bord (a vérifier) et bien sûr au minimum au centre (au moins à 1 (2μs )) pour un changement de mode). Il va sans dire qu’il faut déjà être en ligne-à-ligne pour faire tout ca (bonjour la brochette de registres).
D’ailleurs un détail facilitant la vie… OUTI marche partout mais il PRE-décrémente B. Donc pour le Gate Array., B doit être égal à #80 pour le CRTC (#BE00 -> donnée, #BD00 -> select)
Venons en maintenant à l’adressage des blocs (ce que j’ai expliqué plus haut étant mes expériences d’il y a 2 ans..) Voila le principe (c’est un exemple!)
Hum… j’espère que le schéma t’aide un peu à piger. Bref R0 est à 49 (50μs) durant le main screen (pendant ce temps, et avec une bonne dose d’optimisation R12,R13 et R9 peuvent être changés!)
Puis (c’est une exemple puisqu’il y a d’autre méthodes, notamment la SPLIT 1-8 et la méthode DUNCAN) R0 passe à 1, et le CRTC génère dans la HBL des écrans de 2μs ! (plus petit, ça commence à déconner (c.a.d R0=0 ! … encore que … 1μs …)
Bref, selon le numéro du bloc courant et la valeur de R9 (qui en fait, compte les ruptures) on a :
Dans cet exemple, R9 durant A est mis à 4, ce qui provoque un bloc 3 en B … pas évident, n’est-ce pas?
Il y a cependant des problèmes de CRTC. Sur type 0 il est très dur d’obtenir 7 ruptures en HBL sans anomalie (dans le compteur). Pas mal de contraintes aussi puisque R9 ne doit JAMAIS passer à une valeur inférieure au bloc courant. En fait pour tout dire, le record de blocs indépendants (RVI, Rupture Verticale Indépendante) est de 5, tous CRTCs confondus, et a été trouvé par DUNCAN.Le CRTC type 1 est le mieux armé pour la RV car il ne génère aucun temps entre 2 ruptures verticales (au contraire du CRTC 0, ce qui fait ses problèmes) . Bref si R3 est à 0 sur type 1* et que R0=7 ( 8μs ), on génère un split de 8×8 μs (SPLIT 1-8), ce qui donne:
et permet dont d’avoir tous les blocs sur une ligne, donc d’avoir plus de Ram Vidéo … bien sur … c’est plus chiant à gérer… et ca ne marche pas du tout sur type 0 car même avec R3 à 0, le CRTC génère une zone « visuelle » de 1 octet environ…



(*) Note de Longshot:
Avec le recul, et concernant le SPLIT 1-8 Il est inexact, dans cette situation, d’écrire que R3=0 lorsqu’on splitte en cours d’affichage, car ça suppose que la HBL a lieu. C’était une mauvaise interprétation de ma part : ça marchait car R2 était juste supérieur à 7 dans l’exemple, et il était positionné 1 fois entre 0 et 7 dans une des périodes de 8 µsec pour que l’écran se synchronise. La valeur de R3 n’a aucune importance. Elle doit juste être assez grande pour permettre une bonne synchronisation horizontale du moniteur sur le signal HBL du CRTC.
Je pense que j’ai fait cette confusion car la première fois que j’ai touché à R0 en cours de ligne début 1990, c’était pour changer de mode graphique, et non changer l’adresse. J’étais fasciné par un soft graphique sur Atari ST qui y était arrivé dont je ne me souviens plus du nom. Et lorsqu’on veut changer de mode, une HBL courte au milieu d’une ligne s’impose. Mais pour changer d’adresse, aucune HBL ne s’impose et c’est même à éviter, d’autant que placer R3 à 0 correspond à une longueur de 16 µsec sur certains CRTCs. C’est pourtant ainsi que Overflow a fait sa première rupture en cours de balayage dans l’intro de la S&KOH
Scans






Lorsque l’on souhaite exécuter un programme sur Amstrad CPC, la procédure consiste à utiliser la commande RUN du Basic, qui va se charger de lire des données sur la disquette (ou cassette), les transférer en RAM et de sauter à
]]>Lorsque l’on souhaite exécuter un programme sur Amstrad CPC, la procédure consiste à utiliser la commande RUN du Basic, qui va se charger de lire des données sur la disquette (ou cassette), les transférer en RAM et de sauter à son point d’entrée. Je vous propose d’écrire un petit programme qui sera capable d’être exécuté avec une simple commande LOAD, c’est a dire que le simple fait de le transférer en RAM provoquera son exécution!
Le principe
AMSDOS refuse de charger un fichier dans une zone trop basse. Par contre, si un programme est logé haut dans la RAM, ça passe. Il faut savoir que la pile se trouve en &C000 initialement. A chaque fois que le CPC appelle une fonction il empile l’adresse de retour (ce qui revient à « descendre » dans la mémoire).
Autrement dit, si le basic en &1234 fait un CALL xxxx alors &1237 est placé dans la pile en &BFFF et &BFFE (SP=SP-2). Lorsque la fonction en xxxx sera terminée, elle fera un RET qui récupérera l’adresse &1237 et remettre la pile en &C000 (SP=SP+2).
Ceci étant posé, si l’on charge un fichier logé en &BEBE qui va jusqu’à &C000, et que dans la zone ou se trouve la pile couramment, sont logés des octets &BE, &BE, &BE,&BE….. Le premier RET que le système va faire à l’issue du chargement va amener directement le Z80A en &BEBE et donc démarrer le code chargé.
Le programme
di
ld bc,#7F10
ld hl,#4B5C
out (c),c
noend
out (c),h
nop
out (c),l
nop
jr noend
defs 140,#be ; #bfff-#bebe = 140Si l’on sauvegarde ce code depuis le CPC, il faudra l’assembler à un autre endroit (le programme est relogeable tel quel), le sauvegarder, et modifier le header AMSdos pour que le programme soit logé a la bonne addresse.
Une autre possibilité consiste à utiliser RASM, qui peut directement générer ce DSK avec un header Amsdos correct pour notre fichier :
org #BEBE
start:
di
ld bc,#7F10
ld hl,#4B5C
out (c),c
noend:
out (c),h
nop
out (c),l
nop
jr noend
defs #bfff-$,#be
end:
save 'arg.bin', start, end-start, DSK,'arg.dsk'La preuve par l’image:
La preuve par l’emulation (via TinyCPC) : Démarrer:
Par contre, ce qui n’a jamais été fait, c’est de pouvoir lancer un programme en faisant un CAT. Je pense que c’est impossible… mais qui sait…
]]>Le clavier s’adresse au travers du registre 14 du PPI.
Il y a 10 lignes de clavier qui se partagent le clavier physique et les deux joysticks
Particularité, chaque joystick n’utilise qu’une seule ligne ce qui permet des optimisations agressives pour un programme
]]>Le clavier s’adresse au travers du registre 14 du PPI.
Il y a 10 lignes de clavier qui se partagent le clavier physique et les deux joysticks
Particularité, chaque joystick n’utilise qu’une seule ligne ce qui permet des optimisations agressives pour un programme 100% joystick. Pour ce qui est de la correspondance entre les touches et les lignes de clavier, consultez cette table sur le site du quasar
; routine minimale de lecture d'une ligne clavier
LD BC,#F782 : OUT (C),C ; port A en sortie
DEC B : OUT (C),0 ; validation
LD BC,#F40E : OUT (C),C ; registre 14 sur le port A
LD BC,#F6C0 : OUT (C),C : OUT (C),0 ; selection du registre + validation
LD BC,#F792 : OUT (C),C ; port A en entrée
LD A,ligne_clavier+#40 ; ligne clavier + fonction READ bit 6
DEC B ; B=#F6
OUT (C),A
LD B,#F4 ; adresse du port A
IN A,(C) ; lecture du port A
RET
Cette routine minimale laisse le port A du PPI en entrée (puisqu’on termine la routine par la lecture de l’état de la ligne demandée), ce qui la rend incompatible avec des players de musique. Il devient judicieux de considérer que le port A du PPI est toujours en sortie par défaut vu que c’est ce que considèrent tous les programmes qui jouent de la musique. Ainsi on n’initialise pas le port en sortie en début de routine, mais à la fin!
; routine minimale de lecture d'une ligne clavier
; on considère que le port A est déjà en sortie!
LD BC,#F40E : OUT (C),C ; registre 14 sur le port A
LD BC,#F6C0 : OUT (C),C : OUT (C),0 ; selection du registre + validation
LD BC,#F792 : OUT (C),C ; port A en entrée
LD A,ligne_clavier+#40 ; ligne clavier + fonction READ bit 6
DEC B ; B=#F6
OUT (C),A
LD B,#F4 ; adresse du port A
IN A,(C) ; lecture du port A
LD BC,#F782 : OUT (C),C ; port A en sortie pour tout le monde!
RET
Pour lire plusieurs lignes (toutes les lignes?) il suffit de faire une boucle à partir de l’envoi du numéro de ligne. On utilisera l’instruction INI qui est un IN évolué destiné à être utilisé pour les lectures en rafale d’un port I/O. L’instruction INI pré-décrémente B, lit le port puis écrit la valeur à l’adresse pointée par HL et enfin incrémente HL.
; routine complète et à peu près optimisée de lecture du clavier
; on considère que le port A est déjà en sortie!
; on positionne le tampon clavier de 10 octets en #40
scankeyboard
LD BC,#F40E : OUT (C),C ; registre 14 sur le port A
LD BC,#F6C0 : OUT (C),C : OUT (C),0 ; selection du registre + validation
LD BC,#F792 : OUT (C),C ; port A en entrée
LD HL,#40
LD DE,#F6F4
repeat 10
LD B,D : OUT (C),L
LD B,E : INI
rend
LD BC,#F782 : OUT (C),C ; port A en sortie pour tout le monde!
DEC B : OUT (C),0 ; validation obligatoire pour CPC+
RET
Hlide Fremen, du forum AmstradPlus nous a fait part de ses expérimentations pour essayer de rendre sa couleur d’origine aux touches de son SHARP MZ-700, ans que de son TO8. Avec son autorisation, j’ai regroupé en un seul article toutes ses observations
]]>
Hlide Fremen, du forum AmstradPlus nous a fait part de ses expérimentations pour essayer de rendre sa couleur d’origine aux touches de son SHARP MZ-700, ans que de son TO8. Avec son autorisation, j’ai regroupé en un seul article toutes ses observations sur le sujet…
Le principe
Mon point de départ est cet article qui est lui même inspiré d’une vidéo de The 8-Bit Guy sur le sujet. La technique qui est décrite consiste à utiliser la chaleur plutôt que les UV pour accélérer l’action. Pour ma part, je souhaitais une technique qui se passe des UV en raison de leur effet néfaste sur les polymères. J’ai donc testé cette technique pour avoir une idée de ce que ça donne. Il s’agit d’un expérience de « cuisson » sous vide des touches de clavier avec de l’eau oxygénée.
Pour cela, il faut baigner un sachet contenant de l’eau oxygénée, fermé (zippé ou sous vide), dans de l’eau chauffée à une température constante grâce au cuiseur sous vide (le manche blanc et son tube en inox).

Premier essai
Pour ne pas risquer d’endommager les touches de mon SHARP MZ-700, j’ai préféré y aller progressivement. J’ai effectué le premier essai avec du peroxyde d’hydrogène à 3% (10 volumes), mais sans surprise ce ne fut pas concluant..
J’ai alors relancé l’expérience avec de l’eau oxygénée à 12% (40 volumes). Résultat après une heure et demi sous 60° en solution 12% sans mélange d’eau, les touches avaient l’air plus claires et bien moins jaune. Mais ça ne me semblait pas évident de conclure juste en regardant au travers d’un sac. J’ai donc laissé une heure et demi supplémentaire. Ce n’est qu’en remettant ces touches sur le clavier en comparaison des autres que j’ai pu me rendre compte du résultat :


Il reste encore un peu de jaunissement sur les touches. Fallait-il que j’augmente le temps de l’expérience ? Fallait-il que je j’augmente la température? Le test de the 8-bit guy qui m’a inspiré était à 70° pendant 4 heures.
Les couleurs bleu et orange n’ont pas changé à l’endroit où il n’y avait pas de jaunissement. Pour la touche bleu, ça se traduisait par un bleu sombre légèrement verdâtre. Pour l’orange, ça se voyait pas trop à part l’inscription jaunie.
Un simple bain à 60° à 40 volume a donné le meilleur résultat. Par contre, la touche bleue qui a aussi servi dans la première expérience semble avoir le plus dégusté alors qu’à la sortie de la première expérience, elle n’était guère différente des autres : la partie sombre verdâtre a nettement éclairci par rapport à la base non décolorée. Mais un coup d’œil avec la lumière du jour montre que l’autre touche bleu a encore un jaunissement mais plus faible. J’aimerais pouvoir être optimiste en me disant que cet éclaircissement est lié à la présence de ce jauni mais je ne ferais pas ce pas.
Donc, j’ai l’impression que l’action attaque bien la partie jaunie et qu’il y a un certain exercice à faire pour éviter ce blanchissement. Cela passerait sans doute par une température moins élevée et un accroissement du temps. Ou alors il faut une température un peu plus élevé mais avec un temps plus court.
Ceci dit, ça donne bien sur les touches blanches avec l’inscription noir. J’imagine que pour les touches du TO8 et ceux du CPC 6128, ça donnerait bien aussi.
Au tour du TO8
Pour les touches du TO8, j’ai augmenté à 65°, mais pas plus de 2 heures. Je conseille même moins et de le faire en plusieurs fois en renouvelant l’eau oxygénée dans le sac. Il faut à chaque fois vider le sac, rincer les touches, et si le résultat n’est pas satisfaisant, renouveler l’eau oxygénée dans le sac et recommencer la cuisson.
Le TO8 Avant:

Et Après:
Je précise qu’il n’y a aucune décoloration sur les touches – ni la jaune, ni les grises : les couleurs sont homogènes. Mais on voit toujours une différence avec la couleur d’origine sous les touches. Je n’avais plus d’eau oxygénée pour faire une troisième passe et au final, ce n’est pas plus mal car ça colle bien avec la couleur de la coque qui elle n’a pas bénéficié du traitement. Le résultat n’est vraiment pas désagréable à regarder.
L’action paradoxale de l’UV dans le retrobright
L’intérêt de cette technique, c’est qu’elle se fait sans UV. L’UV casse les polymères. Dans le cas d’une touche, on peut voir ça comme le creusement de nano-tunnels qui favoriseraient la formation de bromine au contact de l’air, responsable du jaunissement en surface.
L’UV s’accompagne de libération d’énergie sous forme de chaleur qui accélérerait la formation de la bromine en migrant plus facilement vers la surface via les “nano-tunnels”. Donc, le fait de “retrobright-er” avec de l’UV devrait amplifier le phénomène du jaunissement en l’absence de l’eau oxygénée.
C’est pourquoi je pense qu’à partir du moment où un plastique a été exposé fortement à de l’UV, il redeviendra inexorablement jaune, même dans une pièce noire humide et chaude.
Par contre, sachant que certaines zones des touches ont jauni parce qu’elles ont été exposées, je vais me servir de la chaleur et de l’eau oxygénée pour faire remonter la bromine et la détruire sans aggraver la situation (je l’espère du moins) car j’ai noté que les parties non exposées ne bougeaient pas (la couleur restait la même que celle d’origine).
Concernant la bromine, je présume qu’elle va polluer l’eau oxygénée. En temps normal, l’eau oxygénée produit de l’eau et de l’oxygène à la fin :
2 H2O2 → 2 H2O + O2
L’eau est jaunie quand on la sort et il y a une légère odeur mais heureusement non persistante. On peut espérer que la bromine est « extraite » du plastique.
Conclusion
Pour finir, le principal défaut de cette méthode c’est qu’elle agit uniquement en surface, contrairement aux UV, qui creusent bien plus profond mais avec l’effet paradoxale que l’on lui connait. Je verrai bien comment ces touches vont évoluer dans le temps.
Mon CPC 6128 a des touches jaunies, j’envisage de lui faire subir un traitement de ce type. J’ai bien songé à faire aussi la coque du TO8 mais je pense qu’il faut disposer d’un sac plastique assez grand et d’un grand bac qui peut supporter 70° sans broncher. Il faudrait vraiment fermer le sac – je ne suis pas sûr qu’un zip soit suffisant si on doit plonger tout le sac dans l’eau.
Liens
- Les agents oxydants non halogènes sur fao.org
- Discussions sur le forum system-cfg;