SNA plus aucun secret



En cet été 2025, il fait chaud, quoi de mieux que d'être tendance en s'adonnant un peu au vibe coding? La page Wikipedia consacrée définit la chose ainsi:
Le vibe coding (litt. « programmation au ressenti ») est une technique de programmation utilisant l'IA dans laquelle une personne décrit à un grand modèle de langage (LLM) étant capable d'écrire du code, un problème en quelques phrases sous la forme d'une invite.
Dans cette courte série de billets, nous allons essayer de créer quelques outils autour de l'Amstrad CPC, en se faisant aider par des modèles d'IA. On va voir cela avec un premier petit projet, qui consiste à créer un analyseur du contenu des fichiers au format SNA, ici assisté par Gemini Flash 2.5. Pour les plus pressés, le code du projet peut être trouvé ici:
et le dépôt git pour récupérer la dernière version:
Et d'emblée, il faut émettre un gros bémol: même si le code produit a été fortement assisté par une IA générative, il aura fallu fortement repasser derrière, car les limites (du moins actuelles) ont rapidement été atteintes, et ce, même pour des tâches plutôt simples. Autant pour démarrer, cela peut être un gain de temps, autant les laisser faire peut être désastreux. Autrement dit, ces outils peuvent être puissants, mais uniquement si vous connaissez le domaine dans lequel vous les faites travailler, pour être capable de les évaluer. Sinon cela peut rapidement devenir catastrophique et contre productif!
Format SNA: kesako?
Le format SNA est très couramment utilisé dans le monde de l'émulation CPC, Il a été initialement défini pour le vénérable émulateur CPCEMU, par Marco Vieth, et a été étendu par la suite par Ulrich Doewich, Martin Korth, Richard Wilson et Kevin Thacker. Le format est décrit dans le menu détail sur cette page du PC wiki .
On ne va pas ici plonger dans les méandre du format, surtout que notre script sert justement à le décortiquer. Ici il s'agira surtout de mettre en relief quelques éléments clefs de l'interaction avec l'IA qui a permis d'obtenir notre script. En gros, ce qu'il faut retenir du format:
- Le fichier commence par un header de 256 octets, donc une centaine environ contient des informations comme l'essentiel des valeurs des registres hardware, le reste étant réservé pour des usages futurs
- Ce header est suivi d'un dump complet de la RAM.
- Trois versions du format existent, essentiellement avec des ajouts d'information dans le header, et la possibilité de compresser certains blocs mémoire dans la 3eme version.
- Il existe la possibilité d'ajouter des blocs de données ('chunks') supplémentaires, ce qui permet d'étendre le format. Certains sont standards ("MEM", "CPC+") d'autres sont spécifiques à certains émulateurs. Ils permettent de préserver des données pour leur bon fonctionnement.
L'IA entre en action
Voici le prompt soumis, ici à Gemini Flash 2.5 avec la fonction canvas activée:
Un fichier SNA est une sauvegarde d'état de la mémoire d’un ordinateur Amstrad CPC, permettant de restaurer l'état complet au moment précis où il a été sauvé (pour reprendre à un moment d'un jeu par exemple). Écris une page web en HTML et JavaScript pour parser un fichier .sna et afficher les informations qu'il contient. Le format de fichier est décrit ici : https://www.cpcwiki.eu/index.php/Format:SNA_snapshot_file_format
Le réponse :
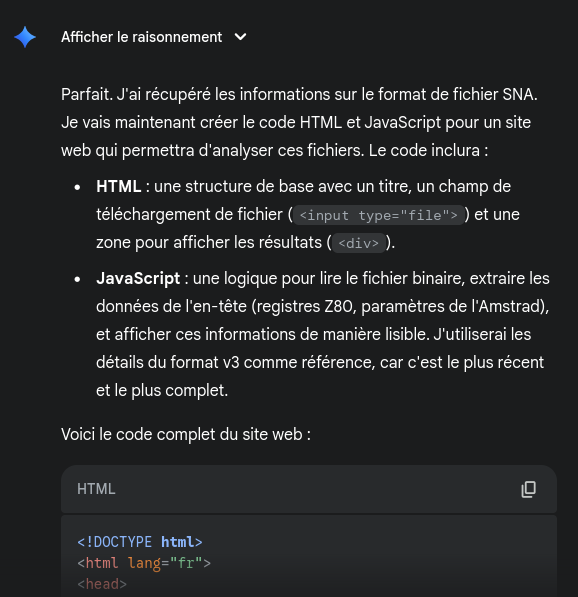
La structure de la page générée était propre, permettait d'ouvrir un fichier SNA, et d'afficher la valeur de certains registres contenu dans le SNA. L'IA a réussi à extraire une liste des champs principaux du SNA à partir de la page wiki, cela commençait bien à première vue. Mais en y regardant de plus près, force est de constater qu'elle n'a pas réussi du tout à:
- Extraire les bons offsets. Autrement dit les valeurs affichées pour les registres, c'était n'importe quoi, et dans le désordre!
- Exploiter le champ qui indique la version du format, au lieu de cela c'est la taille du fichier SNA qui a été prise en compte, ce qui n'est pas du tout fiable. Cela a provoqué la plupart du temps une mauvaise détection de la version
- comprendre que les différents formats étaient très proches et avaient un tronc commun. Résultat, le code généré n'était pas factorisé.
Et c'est la où j'ai pu constater que ces LMMs peuvent être parfois fort têtus! On a beau corriger les bugs (directement sur le canvas), leur indiquer ce qui ne va pas, avec des exemples concrets (tel bloc de registre commence à tel offset, utiliser le bon champ pour la version): rien n'y fait! L'IA a eu beau s'excuser platement, et indiquer que les remarques ont été prises en compte, elles a continué à persister dans l'erreur!

De même, les différents formats de fichier SNA ont une structure commune, mais l'IA ne pouvait s'empêcher de créer un code spécifique à chaque format de fichier, et lui faire remarquer, même à plusieurs reprises, c'était comme siffler dans un violon!
S'ajoute à cela, une grande verbosité, de la duplication de code, et plus globalement un manque d'abstraction, il était temps d’arrêter les frais!
Reprise en main par l'humain
C'est à ce moment que j'ai pris la main sur le code, car je voyais bien que certaines limites avaient été atteintes. Probablement qu'avec des modèles plus puissants ces limites auraient été repoussées, mais cela ne ferait que déplacer le problème. On se heurterait rapidement à un mur avec un projet plus ambitieux, celui ci étant somme tout assez simple.
A ce stade, persister à faire du 'vibe coding' aurait été une pure perte de temps. C'était le bon moment pour finaliser le code, la base était bonne. Et cela n'a pas pris beaucoup de temps, l'essentiel a consisté à vérifier la validité des informations affichées, et corriger en conséquence. Comme dans tout projet informatique, il faut consacrer une part importante du temps dans le test.
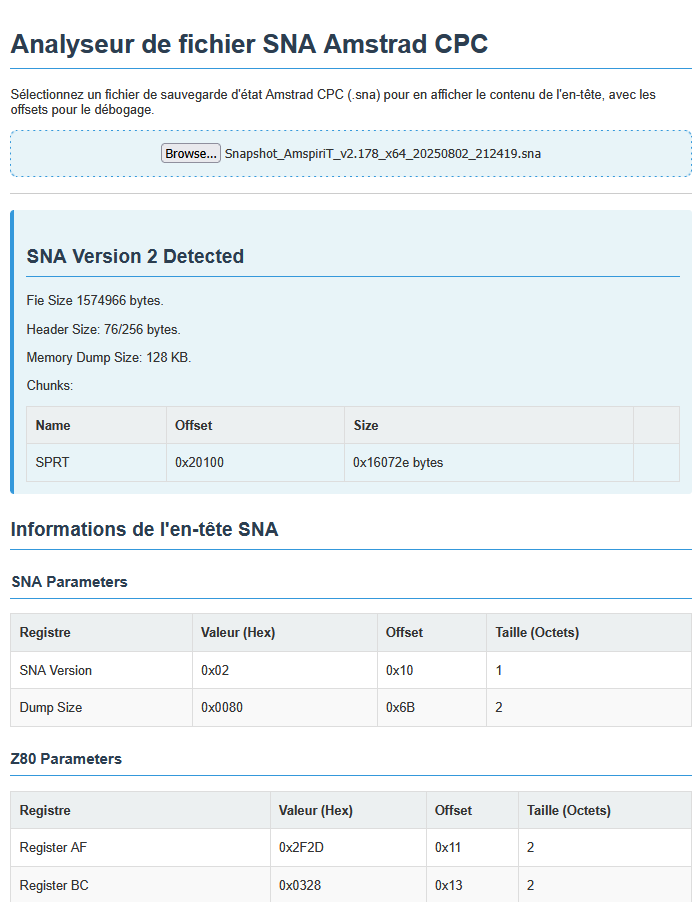
A noter que j'ai testé une fonction qui consiste à faire ajouter par l'IA une façon d'utiliser l'API Gemini dans le code généré, ce qui a conduit à l'ajout d'un bouton pour demander à un modèle plus puissant d'analyser le résultat fourni par le script. Ce bouton sera retiré de la version sur le dépôt Github, mais je l'ai laissé dans le script partagé ci dessus.
Ré-évaluation
Par curiosité, j'ai voulu soumettre le script fonctionnel à la même IA pour lui montrer ce qu'elle aurait du produire, et éventuellement qu'elle fasse des commentaires. Je l'ai fait dans une autre instance, pour qu'elle ne soit pas polluée par le contexte des échanges précédents.
Voici un script d'analyse du format de fichier SNA, qui est utilisé par les émulateurs Amstrad CPC. Il a été généré en partie par Gemini, mais j'ai du le remanier, car les offsets n'étaient pas correct. Que penses tu du code, et que pourrait on y ajouter?
ce à quoi l'IA a répondu:

Sauf que... j'avais omis de soumettre le script! Le LMM a donc évalué du code qu'il n'a pas pu lire! Cela ne lui a pas du tout empêché de faire des commentaires et des compliments. Sans parler du code généré qui était en python, et ne marchait pas du tout! Après partage du bon fichier, voici sa réponse, du bon cirage de pompes:
L'IA ne se doutait pas qu'elle s'envoyait des fleurs, une partie du code étant de son fait, dont l'idée d'intégrer l'API Gemini. Bien sur l'IA a proposé d'apporter des modifications:

Et le résultat, c'est que l'IA a tout saccagé, à savoir remettre les mauvais offsets pour les champs contenus dans le leader, et dé-factorisé une partie du code, en dupliquant le code inutilement pour les différentes versions du format! Je n'ai gardé que l'affichage de la palette de couleurs, et encore en devant en réécrire une partie, mais le reste : direction poubelle!
Conclusion
Globalement, c'était tout de même un exercice plaisant, et plutôt positif: entre le temps où l'idée de se doter d'un petit outil d'analyse de SNA a germé et le moment où l'outil est devenu fonctionnel, il n'aura fallu que quelques heures, alors que le format m'était inconnu. Et cela a aussi permis de ne pas commencer par une page blanche, et a fourni un cadre de départ, ce qui est motivant.
Certains éléments du "code" HTML ne sont pas très intéressants à écrire soi même, les déléguer était une bonne chose, et pour cela le LMM n'a pas eu de souci. Mais sans prendre la main à un moment, il aurait été difficile d'avoir quelque chose de fonctionnel.
Le code remanié est plus structuré, plus compact et probablement plus maintenable. On peut toujours faire mieux, mais il faut s'avoir s'arrêter a un moment!
Et concernant l'utilisation des LMMs d'une façon plus générale, il faut procéder avec précaution, et ne pas se contenter du résultat proposé, malgré des réponses cohérentes en apparence. Certains écueils rencontrés auraient probablement été évités en utilisant d'autres modèles plus puissants, mais cela ne change pas fondamentalement la donne. Ces IA répondent toujours, quitte à dire n'importe quoi, comme on a vu avec le code que j'ai oublié de partager.
Il ne faut donc surtout pas se laisser griser par l'apparente efficacité de ces outils. Il faut tester rigoureusement le résultat obtenu, sinon c'est la garantie d'un véritable désastre, et in fine une perte de temps. Ce sont donc des outils puissants, mais à ne manier que dans des domaines dans laquelle on a déjà une expertise.



